📝 Paper Summary
Large-Scale Reinforcement Learning for LLMs
Reasoning Models (Chain-of-Thought)
DAPO is an open-source reinforcement learning system that stabilizes large-scale reasoning training by decoupling clipping bounds, dynamically sampling informative prompts, and shaping length-based rewards.
Core Problem
Reproducing state-of-the-art reasoning models like DeepSeek-R1 is difficult because standard RL algorithms (PPO, GRPO) suffer from entropy collapse, training instability, and reward noise when scaled to long chain-of-thought tasks.
Why it matters:
- Key technical details of top reasoning models (OpenAI o1, DeepSeek R1) are concealed, hindering community reproduction
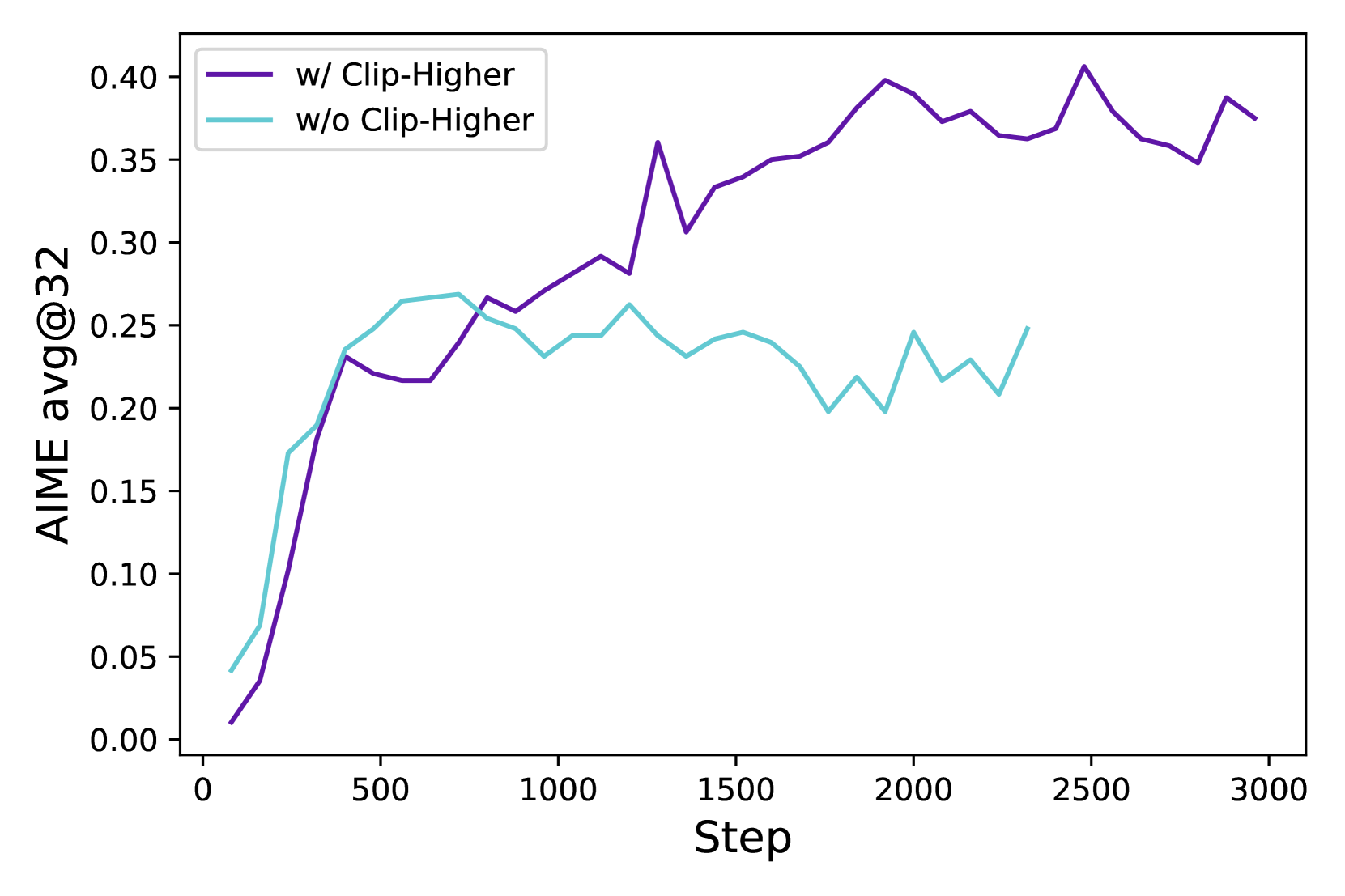
- Naive application of algorithms like GRPO leads to rapid entropy collapse, where the model stops exploring and outputs deterministic, suboptimal responses
- Zero-gradient samples (where all outputs are correct or incorrect) waste up to 50% of computational resources during training
Concrete Example:
When training Qwen2.5-32B with standard GRPO, the policy entropy collapses quickly, causing the model to generate nearly identical responses for a prompt. This prevents it from exploring complex reasoning paths, stalling accuracy at 30% on AIME 2024 compared to 50% with DAPO.
Key Novelty
Decoupled Clip and Dynamic Sampling Policy Optimization (DAPO)
- Decouples the PPO clipping range: uses a higher upper bound to allow low-probability 'exploration' tokens to increase their likelihood faster, preventing the model from getting stuck in local optima
- Dynamically filters out 'zero-gradient' prompts (where all group responses have identical rewards) during rollout, ensuring every training batch contains only informative samples with variance
- Shifts from sample-level to token-level loss weighting to ensure long Chain-of-Thought sequences influence updates proportionally to their length
Architecture
The DAPO training loop logic
Evaluation Highlights
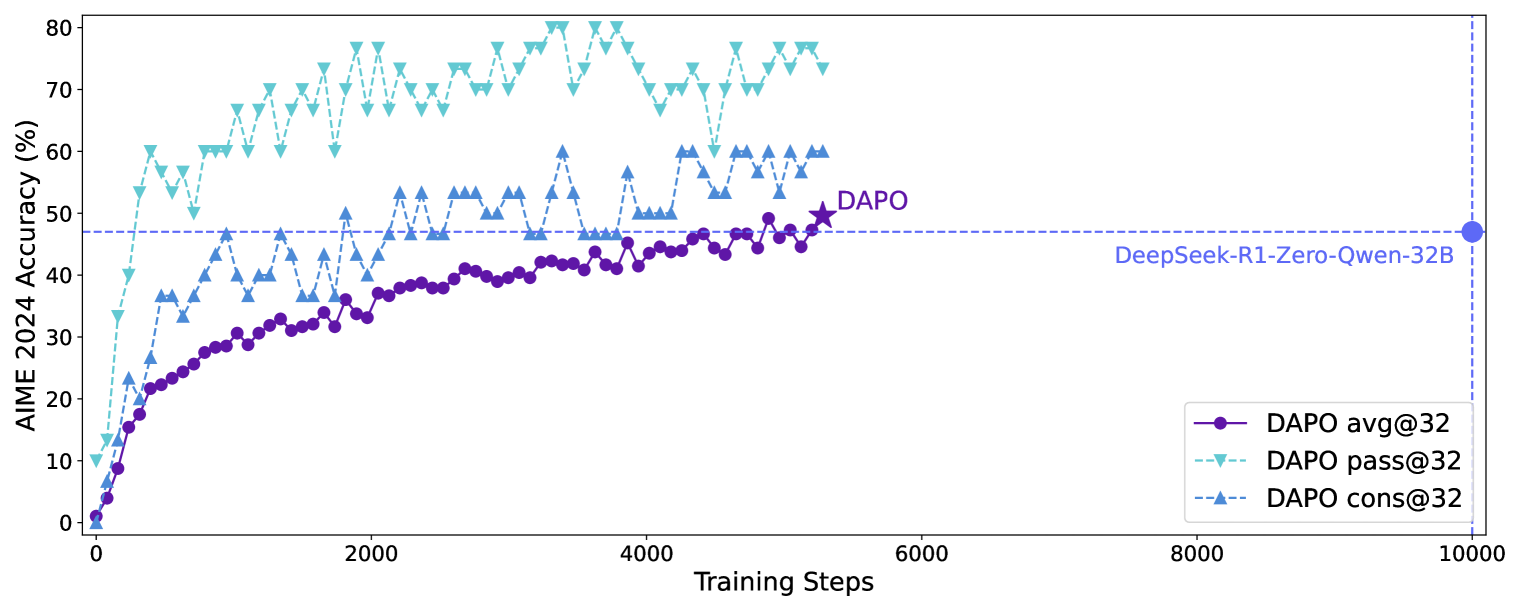
- Achieves 50.0% accuracy on AIME 2024 using Qwen2.5-32B, surpassing the 47% reported by DeepSeek-R1-Zero-Qwen-32B
- Outperforms naive GRPO baseline (30% accuracy) by 20 percentage points on AIME 2024
- Reaches state-of-the-art performance using only 50% of the training steps required by DeepSeek-R1-Zero
Breakthrough Assessment
9/10
Significantly democratizes 'O1-like' reasoning training by open-sourcing a stable, reproducible recipe that matches or beats proprietary baselines with greater efficiency.