📝 Paper Summary
Medical LLMs
Reasoning capabilities
Synthetic data generation
FineMedLM-o1 enhances medical reasoning by training on synthetic long-form reasoning data and utilizing Test-Time Training (TTT) to adapt the model to specific problems during inference.
Core Problem
Existing medical LLMs struggle with deep reasoning required for complex problems (e.g., differential diagnosis) because datasets lack logical chain-of-thought structures and o1-style long-form reasoning traces.
Why it matters:
- Current medical datasets lack robust logical structures, leading to fragile models that fail at critical thinking
- Complex medical problems require comprehensive reasoning to reach reliable conclusions, not just direct answers
- Without reasoning capabilities, LLMs are prone to medical errors and hallucinations in high-stakes healthcare scenarios
Concrete Example:
When presented with a complex instruction requiring differential diagnosis, a standard model might provide a direct, potentially incorrect answer. In contrast, a model trained with reasoning data produces a 'chain of thought'—analyzing symptoms step-by-step and ruling out conditions—before concluding, as illustrated in the paper's comparison of direct vs. reasoning responses.
Key Novelty
Medical Test-Time Training (TTT) and o1-style Synthetic Data
- First application of TTT in the medical domain: the model retrieves relevant reasoning data and fine-tunes itself on the fly during inference to better adapt to the specific problem context
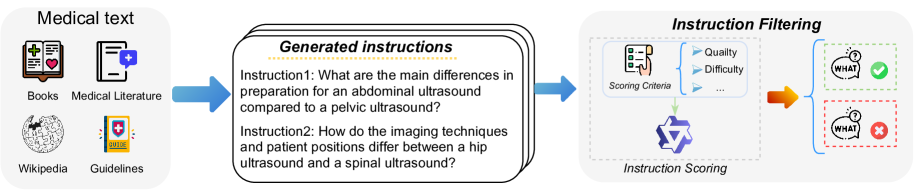
- Creation of FineMed, a large-scale synthetic medical dataset containing 'o1-style' long-form reasoning traces generated by advanced reasoning models (QwQ) to teach deep thinking
Architecture
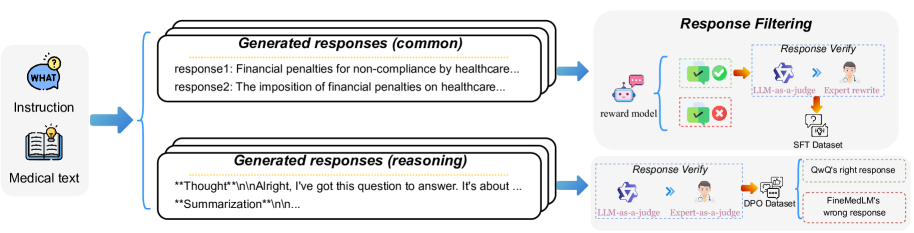
The complete training and inference workflow including SFT, DPO, and the Test-Time Training (TTT) mechanism.
Evaluation Highlights
- Achieves a 23% average performance improvement over prior models on key medical benchmarks (aggregated result from abstract)
- Test-Time Training (TTT) provides an additional 14% performance boost during inference
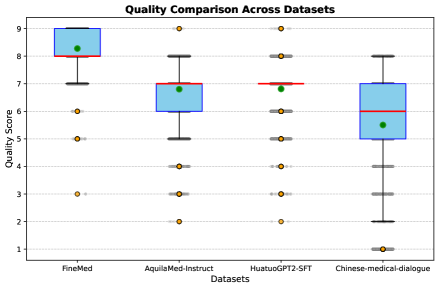
- FineMed dataset achieves higher quality and complexity scores compared to open-source baselines like AquilaMed-Instruct and HuatuoGPT2-SFT in LLM-as-a-judge evaluations
Breakthrough Assessment
8/10
Introduces Test-Time Training to the medical domain and constructs a high-quality synthetic dataset with long-form reasoning, addressing a critical gap in medical LLM reasoning capabilities.