📝 Paper Summary
Mathematical Reasoning
Supervised Fine-Tuning (SFT)
Reinforcement Learning Initialization
CFT improves LLM reasoning by limiting gradient updates to 'critical' tokens—identified via counterfactual perturbations—thereby preventing the suppression of valid alternative reasoning paths caused by uniform supervision.
Core Problem
Standard Supervised Fine-Tuning (SFT) uniformly penalizes all tokens in a response, even though only a small subset determines correctness.
Why it matters:
- Uniform supervision forces models to memorize 'filler' tokens or specific phrasing, reducing output diversity and generalization
- Penalizing valid alternative reasoning paths (that differ from the gold reference but are logically correct) erodes the pre-trained model's exploration capabilities
- Models initialized with low-diversity SFT perform poorly in subsequent Reinforcement Learning (RL) stages due to premature convergence
Concrete Example:
In a math problem, a correct solution might start with 'First, we calculate...' vs 'To solve this...'. Standard SFT penalizes the model for choosing the 'wrong' synonym even if the logic is correct. CFT ignores these tokens, updating only on the numbers or operators where a change would actually flip the final answer to incorrect.
Key Novelty
Critical Token Fine-tuning (CFT)
- Identifies 'critical' tokens by checking if changing them (via counterfactual perturbation) causes the final answer to become incorrect
- Applies a masked loss function that only updates the model weights on these critical tokens, ignoring the rest
- Uses parallel decoding to evaluate multiple token positions simultaneously, speeding up the identification process significantly
Architecture
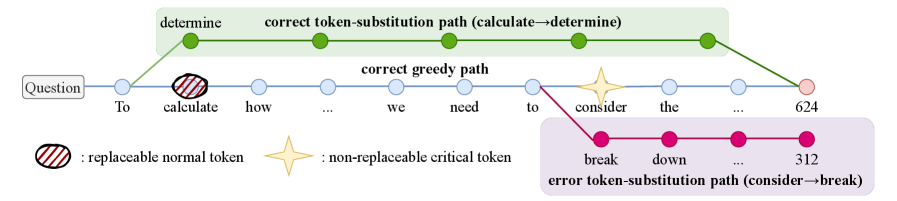
Conceptual workflow of identifying critical tokens via counterfactual perturbation.
Evaluation Highlights
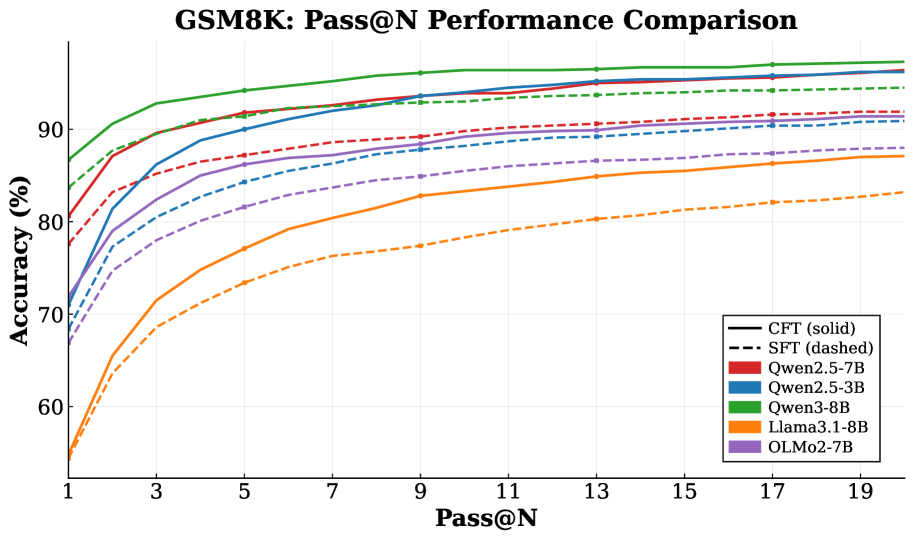
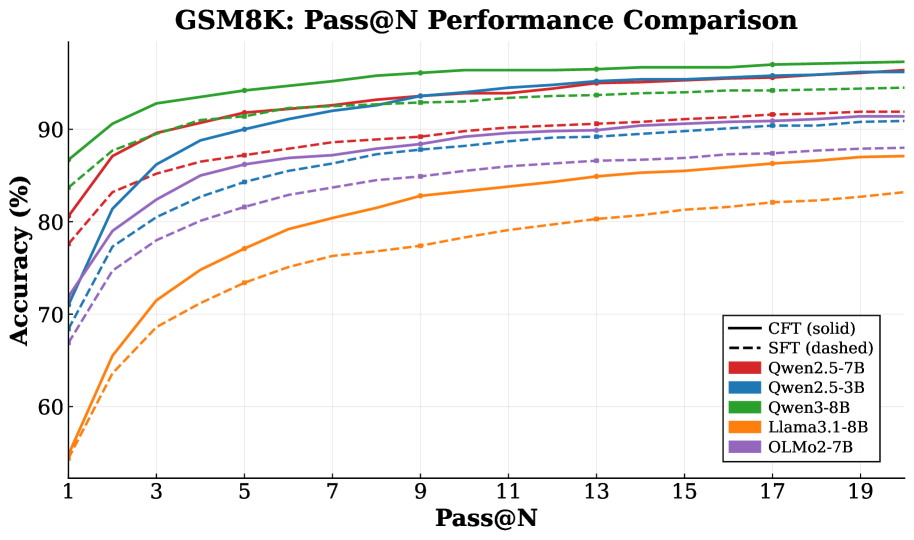
- Achieves consistent performance gains over standard SFT across 11 mathematical reasoning benchmarks using Qwen, Llama, and OLMo backbones
- Maintains superior performance while training on less than 12% of the total tokens compared to standard SFT
- Accelerates the critical token identification process by over 25x on Qwen2.5-7B via parallel decoding compared to serial rollouts
Breakthrough Assessment
7/10
A strong, logically sound method that addresses a fundamental inefficiency in SFT. The counterfactual approach is intuitive and the efficiency gains (12% tokens) are significant, though it relies on an offline preprocessing step.