📊 Experiments & Results
Evaluation Setup
Controlled arithmetic reasoning task with distinct ID and OOD variations
Benchmarks:
- GeneralPoints (ID) (Arithmetic Reasoning (24-point game))
- GeneralPoints Variation (OOD) (Arithmetic Reasoning (Modified card values))
Metrics:
- Accuracy (ID and OOD)
- Loss (ID and OOD)
- Principal Angles (between weight matrices)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Performance trajectories show RL recovering OOD accuracy lost during late-stage SFT. | ||||
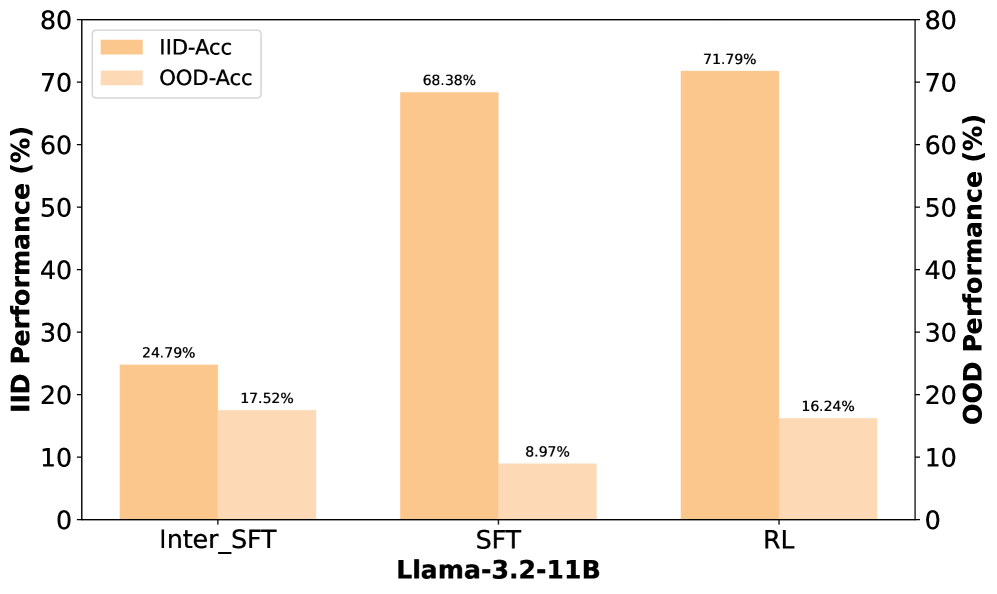
| GeneralPoints (OOD) | Accuracy | 8.97 | 15.38 | +6.41 |
| GeneralPoints (OOD) | Accuracy | 17.09 | 19.66 | +2.57 |
| GeneralPoints (OOD) | Recovery % | 100 | 70-80 | N/A |
Experiment Figures
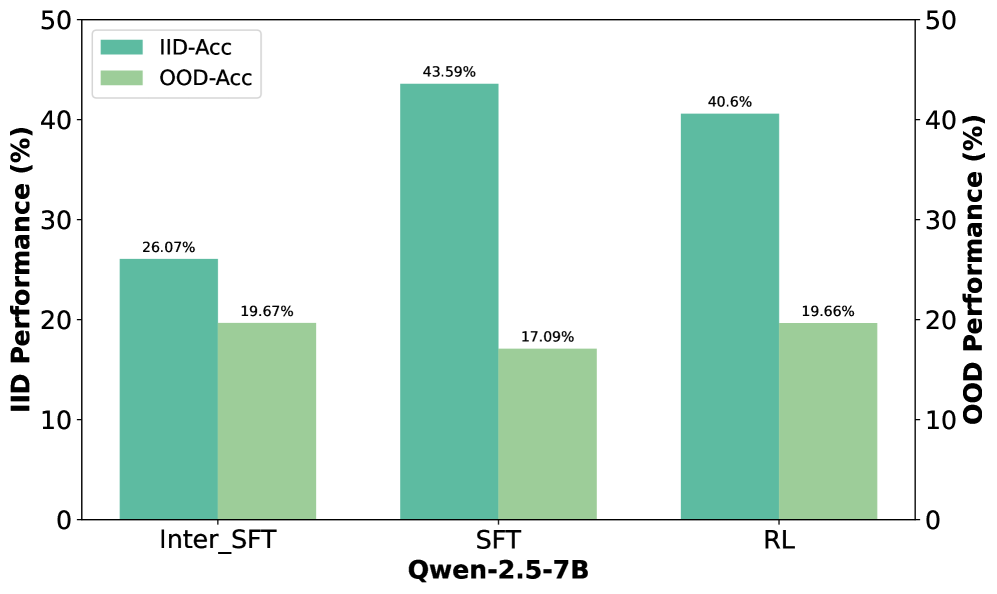
Evolution of OOD vs. ID accuracy across training steps for SFT and subsequent RL
Change in singular values before and after fine-tuning
Main Takeaways
- Better in, better out: Stronger SFT checkpoints (before severe overfitting) allow for better RL rescue of OOD abilities.
- OOD performance peaks early during SFT and then degrades (catastrophic forgetting), while ID performance continues to rise.
- Spectral analysis reveals that singular values (magnitudes) remain stable during both SFT and RL; the "energy" of transformation is preserved.
- Low-rank and shallow layer restoration is surprisingly effective, suggesting forgetting is concentrated in specific high-importance directions.
- If SFT pushes the model into a severe overfitting regime, RL cannot fully recover the lost capabilities (the "point of no return").