📝 Paper Summary
Egocentric Video Understanding
Multimodal Large Language Models (MLLMs)
EgoThinker enables Multimodal LLMs to perform complex first-person reasoning by training on a large-scale egocentric dataset with chain-of-thought annotations and refining grounding skills via reinforcement learning.
Core Problem
Existing MLLMs excel at third-person observer tasks but fail at egocentric reasoning, which requires inferring the camera wearer's hidden intentions and precise hand-object interactions over long temporal horizons.
Why it matters:
- Standard visual reasoning misses the 'embodied' aspect of human cognition (intentions, planning) crucial for robotics and assistants
- Current datasets lack explicit reasoning chains and fine-grained grounding, limiting models to simple event recognition rather than causal understanding
- Egocentric videos span minutes to hours, overwhelming models that cannot track evolving contexts and small details like hand movements
Concrete Example:
In a long video of someone cooking, an observer-centric model might see 'cutting vegetables,' but an egocentric reasoner must infer 'preparing ingredients for a specific stew' based on earlier actions and predict the next step (e.g., 'turning on the stove'). Existing models miss this causal link.
Key Novelty
Two-stage Ego-centric Reasoning Framework with GRPO
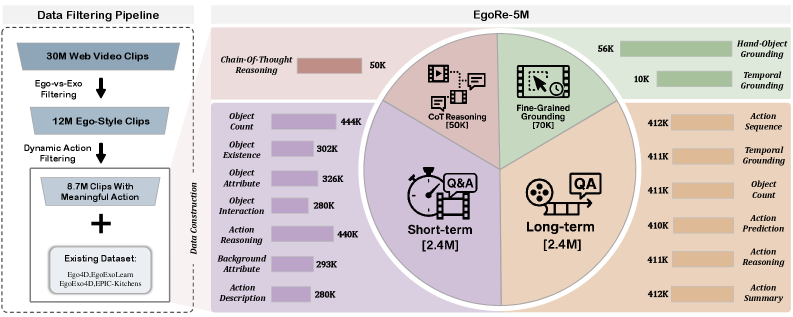
- Curates EgoRe-5M, a massive dataset combining web-mined egocentric clips with synthetic Chain-of-Thought (CoT) rationales and fine-grained hand-object masks
- Applies a two-stage training curriculum: Supervised Fine-Tuning (SFT) for foundational reasoning followed by Reinforcement Fine-Tuning (RFT) using Group Relative Policy Optimization (GRPO) to enforce precise spatio-temporal grounding
Architecture
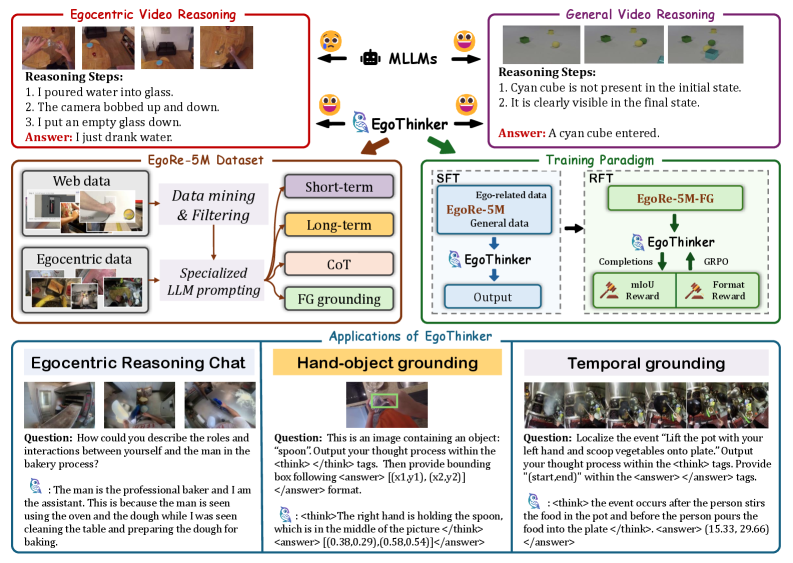
Overview of the EgoThinker framework: from web-scale video mining to dataset construction (EgoRe-5M) and the two-stage training pipeline (SFT followed by RFT via GRPO).
Evaluation Highlights
- Achieves state-of-the-art performance on egocentric QA benchmarks (EgoTimeQA, Ego-QA) and long-term reasoning tasks
- Significantly improves fine-grained hand-object interaction localization compared to existing MLLMs like Video-LLaVA
- Demonstrates that RFT with rule-based rewards (format + IoU) effectively couples high-level reasoning with low-level pixel grounding
Breakthrough Assessment
8/10
Significant contribution in scaling egocentric data (13M clips) and successfully applying RL-based reasoning (GRPO) to the multimodal video domain, showing clear gains in embodied understanding.