📝 Paper Summary
LLM Alignment
Inference-time Alignment
Controlled Decoding
Transfer Q* aligns language models during inference by estimating the optimal target value function using a baseline model aligned with a potentially different reward, avoiding expensive fine-tuning.
Core Problem
Decoding-based alignment requires an optimal token-level Q-function ($Q^*$) which is unavailable; existing methods approximate it using the unaligned SFT model ($Q^{\pi_{sft}}$), causing distribution shifts and sub-optimality.
Why it matters:
- Fine-tuning large models (billions of parameters) is computationally expensive and environmentally costly
- Many state-of-the-art models are closed-source (black-box), making gradient-based fine-tuning impossible
- Existing decoding approximations rely on short-term rewards or unaligned proxies, leading to poor generation quality
Concrete Example:
When asked to convert decimal 31 to binary in JavaScript, a standard decoding method (CD) fails to produce working code, outputting generic text or incomplete loops. In contrast, TQ* accurately generates the specific `toString(2)` method call.
Key Novelty
Transfer Decoding (Direct and Indirect)
- Leverages existing trajectory-level aligned models (e.g., from DPO) to estimate the unavailable token-level optimal value function ($Q^*$) needed for decoding
- Introduces 'Indirect Transfer' to align with a target reward using a baseline model aligned with a significantly different reward, mathematically correcting for the discrepancy
- Provides a hyperparameter to explicitly control the deviation from the reference SFT model, allowing user-defined trade-offs between alignment and original capability
Architecture
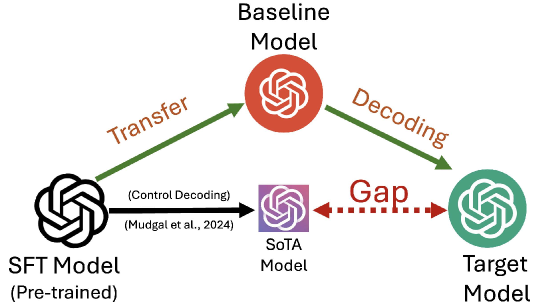
Comparison of Q-value estimation between Controlled Decoding (CD) and Transfer Q* (TQ*).
Evaluation Highlights
- Achieves up to 1.45x improvement in average reward compared to Controlled Decoding (CD)
- Attains a 67.34% win-tie rate against Controlled Decoding (CD) in GPT-4 based evaluations
- Demonstrates superior coherence, diversity, and quality across synthetic and real datasets
Breakthrough Assessment
8/10
Offers a mathematically grounded solution to the 'missing oracle' problem in decoding-based alignment, showing significant empirical gains over current methods like CD without requiring new training.