📝 Paper Summary
Multimodal Large Language Models (MLLMs)
Visual Chain-of-Thought (CoT)
Latent Space Reasoning
Monet enables MLLMs to reason using continuous latent embeddings as intermediate thoughts, optimized via a three-stage distillation pipeline and a novel reinforcement learning algorithm (VLPO) that estimates probabilities for continuous vectors.
Core Problem
Existing visual reasoning methods rely on rigid external tools or auxiliary images, which are computationally expensive to align and difficult to optimize using standard text-based reinforcement learning.
Why it matters:
- Aligning latent embeddings with full auxiliary images incurs high computational and memory costs due to long sequence lengths
- Standard RL methods like GRPO cannot optimize continuous latent embeddings because they lack discrete probability distributions, leaving the 'reasoning' part of the model unoptimized
- External tools (bounding boxes, code) lack the flexibility of human-like abstract visual thinking
Concrete Example:
When answering a complex geometry question, standard CoT might fail to verify spatial relationships. Tool-based methods might crop the image but miss global context. Monet generates continuous 'thought' vectors that implicitly attend to relevant visual features without needing to generate pixels or call external APIs.
Key Novelty
Monet: Latent Visual Reasoning with VLPO
- Replaces discrete text CoT steps with continuous 'latent embeddings' that act as abstract visual thoughts, generated autoregressively by the MLLM
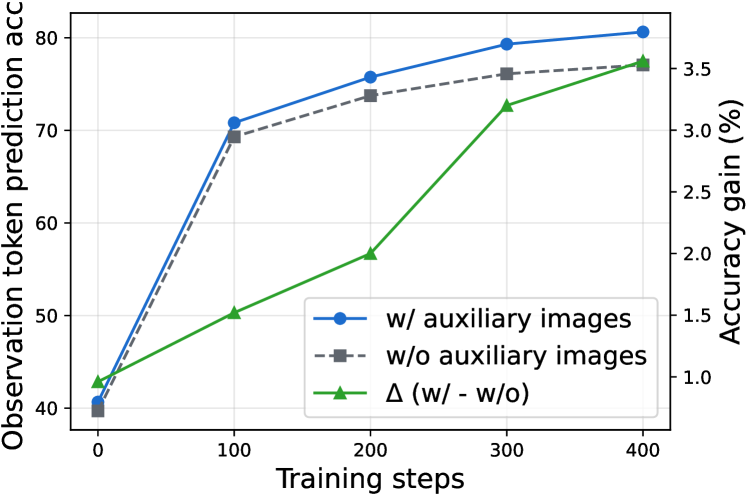
- Uses a 3-stage SFT pipeline with 'Dual Supervision': aligns observation tokens (key visual takeaways) rather than just raw image pixels, and uses controlled attention to distill visual info into latents
- Introduces VLPO (Visual-Latent Policy Optimization), an RL algorithm that treats continuous latent vectors as actions by estimating their probability density using a Gaussian approximation, enabling policy gradient updates on thoughts
Architecture
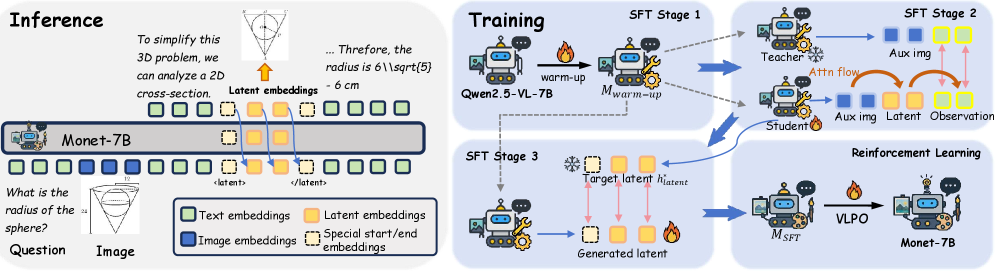
Comparison of Monet's inference process vs. Training pipeline.
Evaluation Highlights
- Constructed Monet-SFT-125K, a dataset of 125,000 real-world, chart, OCR, and geometry samples curated to ensure auxiliary images are both necessary and sufficient for reasoning
- Proposes VLPO to solve the limitation of GRPO, enabling direct optimization of continuous latent embeddings via outcome rewards (correct/incorrect)
Breakthrough Assessment
8/10
Proposes a theoretically grounded solution (VLPO) to a major limitation in latent reasoning (applying RL to continuous tokens) and a robust SFT pipeline. Evaluation metrics are missing from the provided text, but the methodology addresses critical scalability and optimization bottlenecks.