📝 Paper Summary
Chain-of-Thought Reasoning
Reinforcement Learning for LLMs
Curriculum Learning
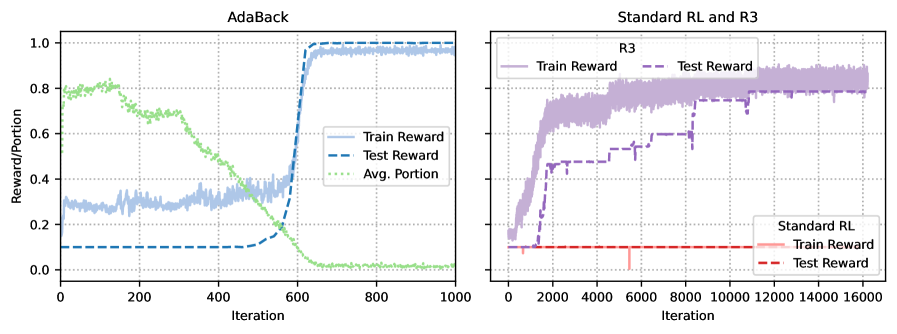
AdaBack enables models to learn complex reasoning chains with sparse rewards by initially revealing solution prefixes and adaptively reducing this supervision per-sample as the model demonstrates competence.
Core Problem
Standard RL fails in long reasoning tasks because the search space grows exponentially, making positive rewards exponentially rare (sparse), while SFT fails to generalize to latent dependencies outside the training distribution.
Why it matters:
- RL fine-tuning often only amplifies existing pre-trained behaviors rather than discovering new reasoning capabilities due to exploration difficulties
- Acquiring dense expert demonstrations for SFT is expensive and scales poorly with sequence length
- Current methods struggle with the 'intermediate regime' between full supervision (SFT) and no supervision (RL), limiting generalization on variable-length tasks
Concrete Example:
In a 'Chain-of-Parities' task with length L=16, a model must generate 32 correct steps. Randomly guessing the full sequence has a probability of 2^-16, providing effectively zero feedback to standard RL. SFT fails to learn the underlying parity logic from limited data. AdaBack solves this by initially revealing 31 steps, making the success probability 0.5 (one step), then backtracking.
Key Novelty
Adaptive Backtracking (AdaBack)
- Treats reasoning chains as a curriculum where the model first learns to complete the final step, then the last two, and so on (reverse curriculum)
- Adjusts the length of the revealed 'hint' (prefix) dynamically for *each specific sample* based on that sample's historical reward, rather than a fixed global schedule
Architecture
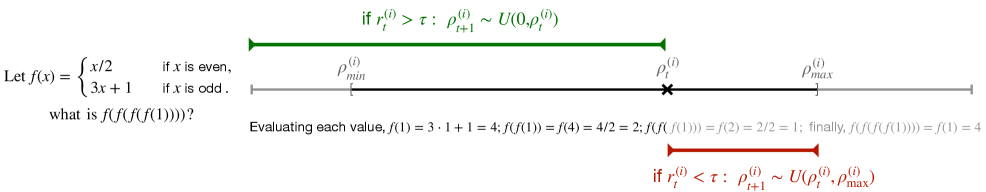
Visualization of the Adaptive Backtracking process showing how the revealed supervision prefix shortens over training epochs.
Evaluation Highlights
- Reliably solves the 'Chain-of-Parities' synthetic task (length 16) where both Standard RL and SFT fails completely
- Demonstrates robust generalization on GSM8k variants (Base-7 and Tensor-2) that introduce symbolic shifts and longer horizons [numeric deltas not in snippet]
- Enables base models to match the performance of SFT-initialized counterparts on mathematical reasoning benchmarks
Breakthrough Assessment
8/10
Proposes a theoretically grounded 'separation result' where this method succeeds while SFT and RL both fail. The per-sample adaptive mechanism addresses the fundamental exploration/exploitation trade-off in reasoning.