📝 Paper Summary
GUI Agents
Visual Grounding
Preference Optimization
LPO improves the spatial precision of GUI agents by optimizing a multimodal policy using Group Relative Preference Optimization (GRPO) driven by novel pixel-entropy and physical-distance rewards.
Core Problem
Supervised Fine-Tuning (SFT) limits GUI agents' spatial perception, while existing RL methods rely on coarse, static thresholds (e.g., bounding boxes) that fail to distinguish varying degrees of positional accuracy.
Why it matters:
- Precise interaction (e.g., clicking exact coordinates) is fundamental for autonomous agents to function correctly in complex user interfaces.
- Current methods like UI-TARS rely on labor-intensive manual data construction for preference optimization.
- Static decision boundaries in prior RL work offer only coarse evaluations, leading to imprecise localization where 'close' is treated the same as 'perfect'.
Concrete Example:
In current approaches, a click 5 pixels away from a button center and a click 20 pixels away might both be classified as 'success' if within a fixed bounding box threshold, or 'fail' if outside. LPO uses continuous distance rewards, incentivizing the agent to correct the 20-pixel error down to 0 pixels for higher reward.
Key Novelty
Location Preference Optimization (LPO)
- Uses 'Window-based Information Density' to guide agents toward information-rich areas (buttons/text) by calculating pixel entropy within grid segments.
- Implements a 'Dynamic Location Reward' based on Euclidean distance to target coordinates, providing granular feedback on spatial precision rather than binary success/fail.
- Integrates these rewards into a Group Relative Preference Optimization (GRPO) framework to explore the GUI environment without needing manually paired preference data.
Architecture
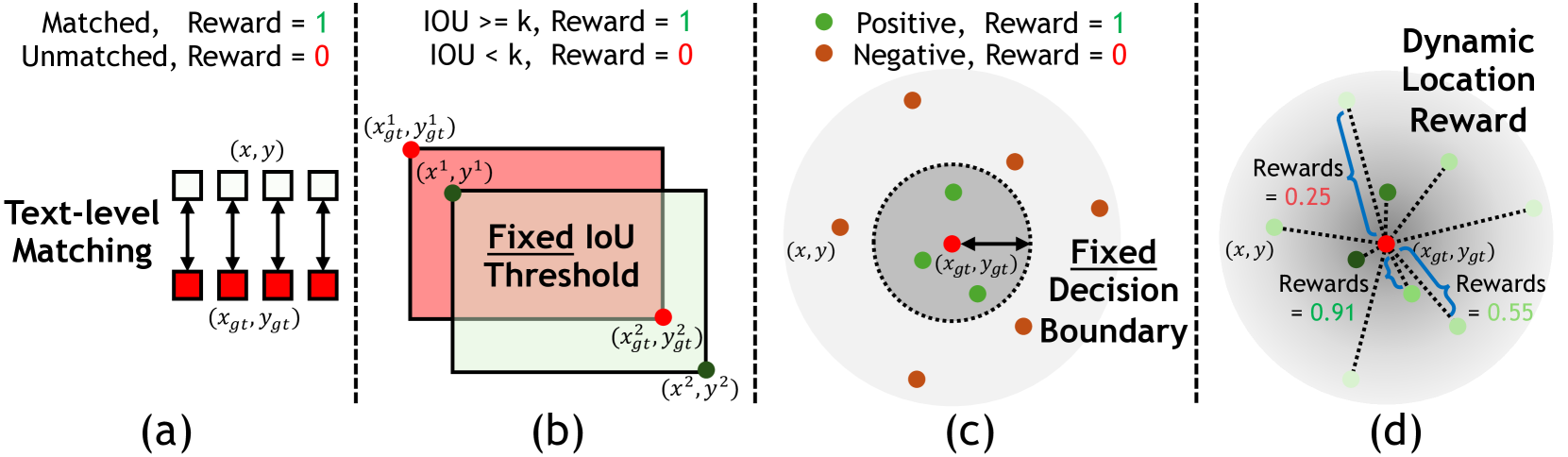
Comparison of different preference optimization strategies (RL with fixed rewards vs. LPO with dynamic rewards) and the proposed reward mechanism.
Breakthrough Assessment
7/10
Introduces a logical, physically grounded reward mechanism for GUI agents that moves beyond binary hit/miss metrics. While the methodology is sound, the text provided does not contain the experimental results to verify the magnitude of improvement.