📝 Paper Summary
Image Captioning
Multimodal Large Language Models (MLLMs)
Visual Reasoning
OmniCaptioner is a unified framework trained on 21 million diverse image-text pairs that converts visual details into dense text, enabling standard LLMs to solve visual reasoning tasks without multimodal training.
Core Problem
Current MLLMs struggle with domain gaps (e.g., between natural images and charts/UIs) and often lag behind text-only LLMs in complex reasoning capabilities.
Why it matters:
- Specialized captioners lack versatility, failing to handle the variety of visual inputs (charts, posters, geometry) needed for general-purpose assistants
- State-of-the-art reasoning models (like DeepSeek-R1) are text-only; bridging the visual gap without expensive multimodal retraining allows leveraging their superior reasoning power
- Inaccurate or sparse captions limit the performance of downstream tasks like text-to-image generation and supervised fine-tuning
Concrete Example:
When asking a standard MLLM (like LLaVA-OneVision) to convert a chart to Markdown, it may hallucinate values due to poor domain alignment. Similarly, asking a geometry question requires reasoning that visual encoders often fail to capture, whereas a precise text description allows a math-optimized LLM to solve it.
Key Novelty
Unified Multi-Domain Captioning as a Universal Connector
- Constructs a massive, diverse dataset (21M) covering natural images, visual text (posters, UIs), and structured visuals (charts, equations) using a two-stage generation pipeline (Seed + Extension)
- Treats visual reasoning as a text-only task by converting images into dense, fine-grained textual descriptions (Pixel-to-Text Mapping), decoupling perception from reasoning
- Demonstrates that feeding these detailed captions into strong reasoning LLMs (like DeepSeek-R1) achieves state-of-the-art visual reasoning without updating the LLM weights
Architecture
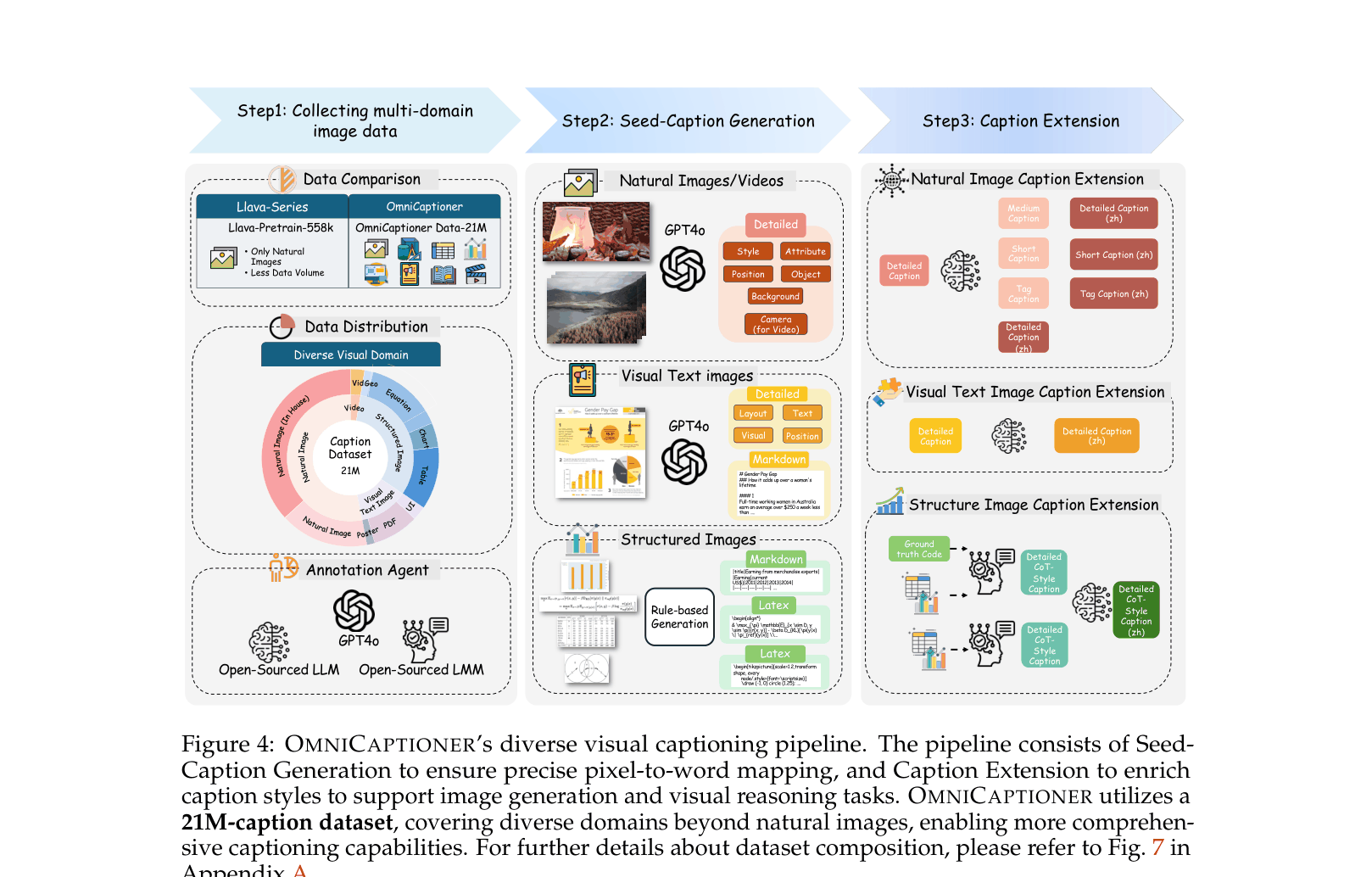
The dataset construction and training pipeline for OmniCaptioner
Evaluation Highlights
- Achieves 40.5% on MathVerse with OmniCaptioner + DeepSeek-R1-Distill-Qwen-7B, significantly outperforming the multimodal Qwen2-VL-7B (31.9%) without visual encoder training
- Surpasses LLaVA-OneVision-7B on captioning metrics (BLEU: 22.35 vs 14.18) and human preference (56.7% win rate on non-natural images)
- Improves Text-to-Image generation on GenEval (Overall score 67.58) compared to using standard Qwen2-VL captions (65.27) or the base SANA model (64.61)
Breakthrough Assessment
8/10
Strong evidence that dense captioning can effectively bridge the gap between vision and reasoning LLMs, outperforming native MLLMs in specific reasoning tasks. The unified dataset approach is highly practical.
