📝 Paper Summary
End-to-end Autonomous Driving
Vision-Language-Action (VLA) Models
AdaThinkDrive uses reinforcement learning to teach autonomous driving models when to use detailed reasoning (Chain-of-Thought) and when to act instantly, balancing trajectory accuracy with computational efficiency.
Core Problem
Existing Vision-Language-Action models for driving apply Chain-of-Thought reasoning indiscriminately, causing unnecessary latency and potential performance degradation in simple scenarios due to 'over-reasoning'.
Why it matters:
- Always-on reasoning increases computational overhead, which is critical for real-time autonomous driving systems
- In simple scenarios (e.g., highway cruising), explicit reasoning steps can introduce hallucinations or uncertainty, lowering decision quality compared to direct prediction
- Current methods lack the flexibility to adapt their inference strategy based on scene complexity
Concrete Example:
In a simple Level 1 scenario (e.g., straight road, no obstacles), a standard CoT model might over-analyze distant, irrelevant objects, increasing latency and potentially predicting erratic behavior. AdaThinkDrive recognizes the simplicity and outputs the trajectory directly.
Key Novelty
Fast Answering / Slow Thinking Mechanism
- Implements a dual-mode strategy where the model learns to either output a trajectory directly (Fast) or generate a reasoning chain first (Slow) based on input complexity
- Uses Group Relative Policy Optimization (GRPO) with an Adaptive Think Reward to dynamically optimize the decision of *when* to reason, rather than relying solely on static rules
Architecture
The AdaThinkDrive framework pipeline, illustrating data preparation, two-stage fine-tuning, and the adaptive reasoning mechanism via RL.
Evaluation Highlights
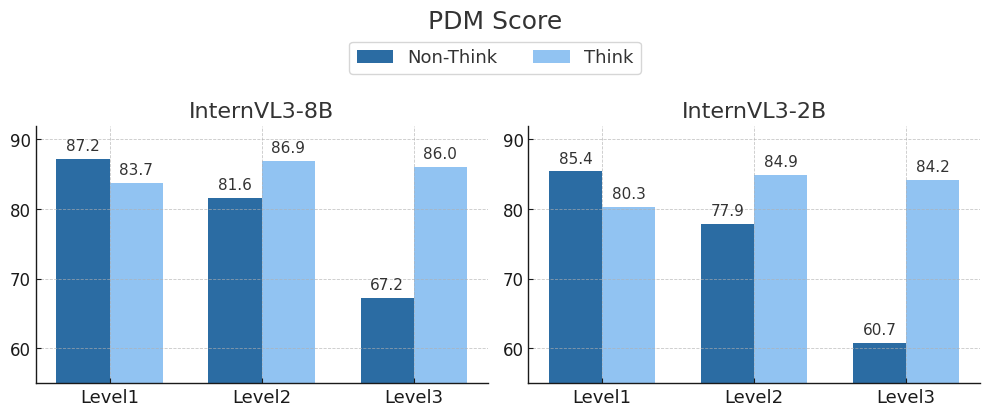
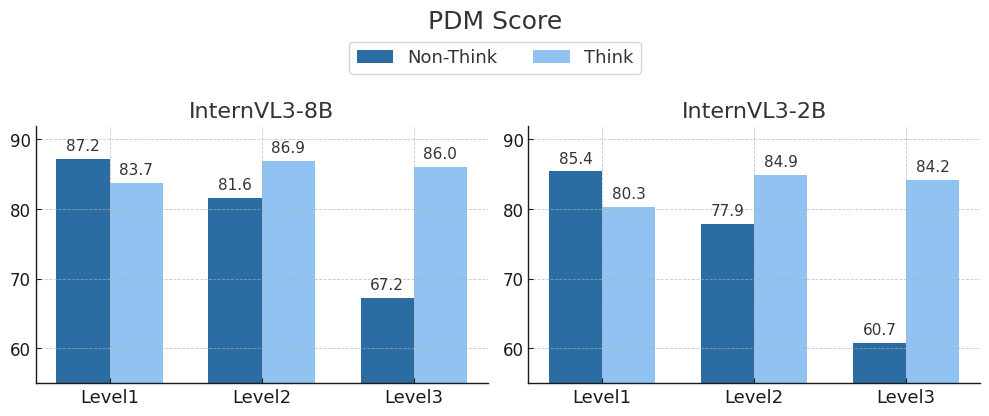
- Achieves 90.3 PDMS on the NAVSIM benchmark, outperforming the best vision-only baseline by 1.7 points
- Surpasses both 'Never-Think' and 'Always-Think' baselines by 2.0 and 1.4 PDMS points respectively, proving the value of adaptive switching
- Reduces inference time by 14% compared to the 'Always-Think' baseline by bypassing reasoning in 84% of simple scenarios
Breakthrough Assessment
8/10
Significantly improves efficiency and accuracy in VLA driving models by solving the 'when to reason' problem. The adaptive RL approach is a strong methodological contribution applicable beyond driving.