📝 Paper Summary
Video Understanding
Multimodal Reasoning
Reinforcement Learning for LLMs
Open-o3-Video enables video language models to generate verifiable spatio-temporal evidence (timestamps and bounding boxes) during reasoning by using a curriculum-based reinforcement learning strategy that prevents spatial reward collapse.
Core Problem
Current video reasoning models generate text without explicit visual evidence, making them hallucination-prone and unverifiable, while existing training methods fail to learn joint spatio-temporal grounding due to reward sparsity.
Why it matters:
- Without explicit timestamps and bounding boxes, complex video reasoning traces (e.g., tracking a specific person through occlusions) are impossible to verify for correctness
- Existing datasets lack unified supervision: they have either timestamps (but no boxes) or boxes (on isolated frames without time), preventing models from learning coherent dynamic localization
- Standard RL fails due to 'spatial collapse': if the model predicts the wrong timestamp, the spatial reward (IoU) is zero/meaningless, preventing the spatial module from ever learning
Concrete Example:
In early training, a model might correctly identify a 'red car' spatially but at the wrong timestamp (t=10s instead of t=5s). A standard reward function calculates IoU against the ground truth at t=10s (where the car isn't present), resulting in zero reward. The model effectively receives no feedback on its spatial capabilities until temporal accuracy is perfect, stalling learning.
Key Novelty
Curriculum-based Spatio-Temporal RL (Adaptive Proximity & Gating)
- Adaptive Temporal Proximity: A curriculum strategy that relaxes temporal precision requirements early in training to provide dense reward signals, then gradually tightens them to enforce precision
- Temporal Gating: A validation mechanism that only calculates spatial rewards when the predicted timestamp is sufficiently close to ground truth, preventing the model from being rewarded for 'hallucinating' correct-looking boxes at the wrong time
- Explicit 'Thinking with Frames': Unlike agent-based tool users, the model natively generates structured evidence tags (<obj>, <box>, <t>) within its reasoning chain in a single inference pass
Architecture
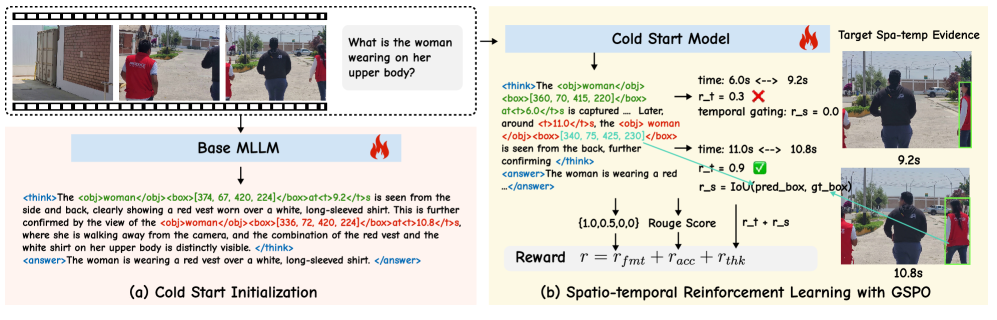
The two-stage training pipeline (Cold Start SFT -> Reinforcement Learning with GSPO) and the reward calculation mechanism.
Evaluation Highlights
- +14.4% improvement in mAM (mean Average Match) on the V-STAR benchmark compared to the Qwen2.5-VL baseline
- +24.2% improvement in mLGM (mean Localized Grounding Match) on V-STAR compared to Qwen2.5-VL, demonstrating superior grounding precision
- Outperforms GPT-4o on V-STAR grounding metrics despite using a smaller 7B parameter base model
Breakthrough Assessment
8/10
Addresses a critical bottleneck in video LLMs (verifiability and joint grounding) with a principled solution to the 'spatial collapse' optimization problem. Strong results on specialized benchmarks.
