📝 Paper Summary
Mask-guided image generation
Reinforcement Learning from Human Feedback (RLHF) for vision
Multi-task learning
OneReward aligns a single image generation model across multiple tasks and conflicting evaluation metrics by using one Vision-Language Model as a reward judge that conditions its feedback on task-specific text queries.
Core Problem
Existing mask-guided generation models rely on task-specific fine-tuning that limits generalization, while current RLHF methods (like DPO) struggle to resolve conflicting preferences across different metrics (e.g., aesthetics vs. structure).
Why it matters:
- Training separate models for inpainting, outpainting, and removal is inefficient and prevents knowledge transfer across related tasks
- Standard preference optimization (DPO) fails when an image wins on one metric but loses on another, as it assumes a single global preference ordering
- Previous reward-based methods (ReFL) require training distinct reward models for each metric (fidelity, safety, etc.), increasing complexity
Concrete Example:
In image editing, a generated output might have perfect aesthetic quality but fail to preserve the structural lines of the background. A standard DPO approach cannot easily label this as a clear 'winner' or 'loser' without metric-specific granularity, leading to ambiguous training signals.
Key Novelty
OneReward: Generative VLM as a Multi-Task Reward Model
- Uses a single pre-trained Vision-Language Model (VLM) to serve as the reward model for all tasks, rather than training separate scalar reward heads
- Conditions the VLM with a text query encoding the specific task (e.g., 'object removal') and metric (e.g., 'consistency'), allowing it to output metric-specific 'Yes/No' preference probabilities
- Eliminates Supervised Fine-Tuning (SFT) by applying Reinforcement Learning directly to the pre-trained base model using these unified reward signals
Architecture
The OneReward training framework pipeline
Evaluation Highlights
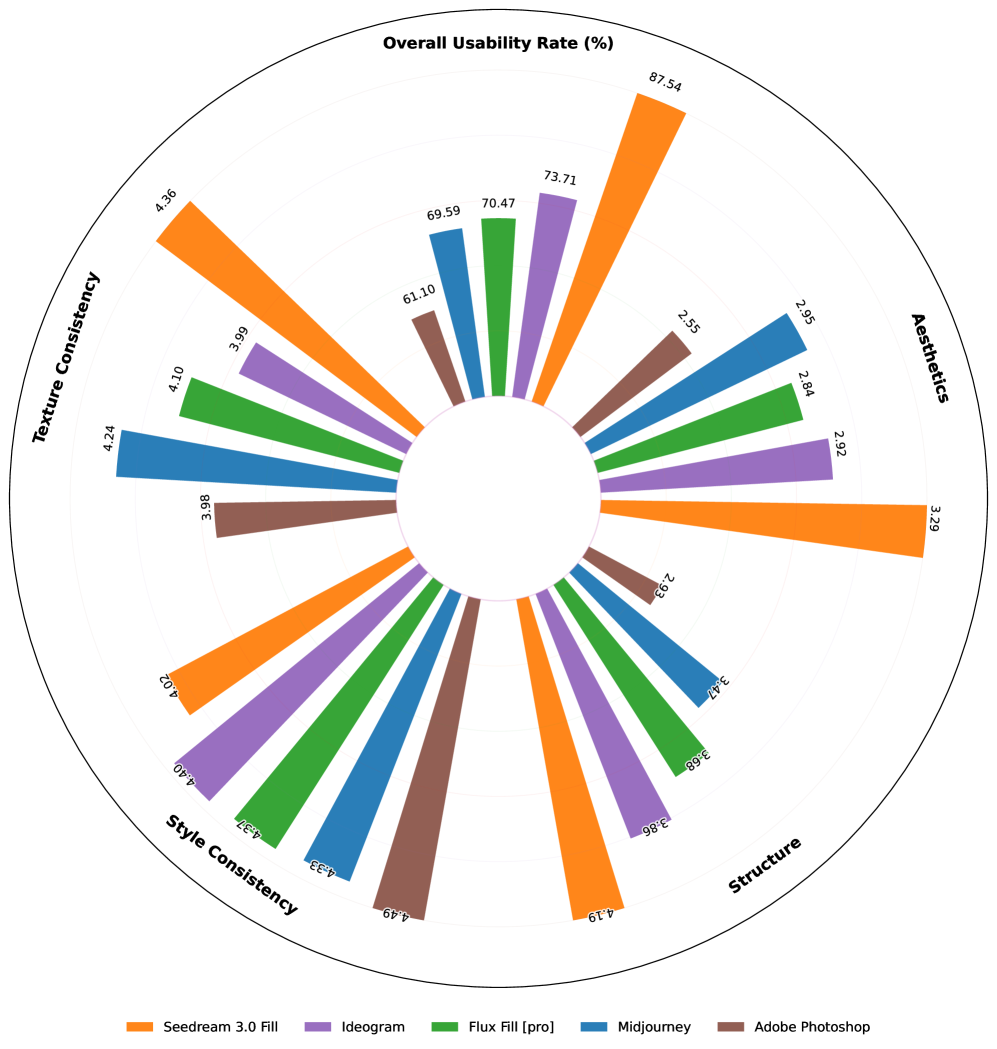
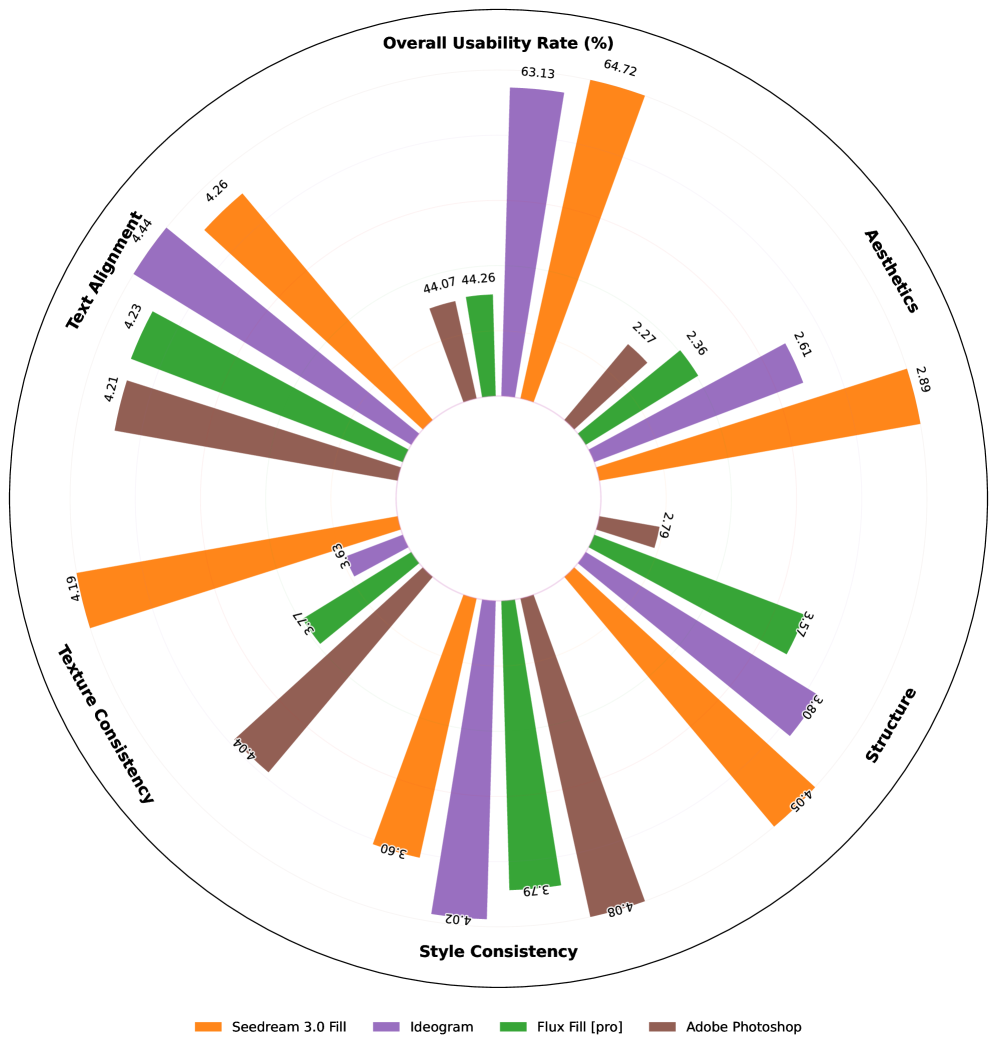
- Reward model achieves 84.93% accuracy in aligning with human judgments for object removal quality
- Reward model exceeds 80% accuracy for text alignment evaluation in both image fill and image extend tasks
- Proposed model (Seedream 3.0 Fill) is claimed to outperform commercial competitors like Adobe Photoshop and Ideogram on alignment and aesthetics (qualitative claim, exact metrics not in snippet)
Breakthrough Assessment
8/10
Proposes a unified RL framework that successfully handles conflicting multi-objective optimization in vision generation without SFT, a significant methodological simplification over prior multi-model pipelines.