📊 Experiments & Results
Evaluation Setup
Models are prompted with RTVLM samples and scored by GPT-4V on a scale of 1-10 based on specific criteria for refusal, accuracy, and safety.
Benchmarks:
- RTVLM (Red Teaming (Safety, Privacy, Fairness, Faithfulness)) [New]
- MM-Hallu (Multimodal Hallucination Evaluation)
- MM-Bench (General VLM Capability Benchmark)
Metrics:
- GPT-4V Eval Score (1-10)
- Human Eval Score
- Statistical methodology: Inter-Annotator Agreement (IAA) calculated for human evaluation (result > 0.7).
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| RTVLM (subset) | Inter-Annotator Agreement (IAA) | 0.0 | 0.7 | +0.7 |
Experiment Figures
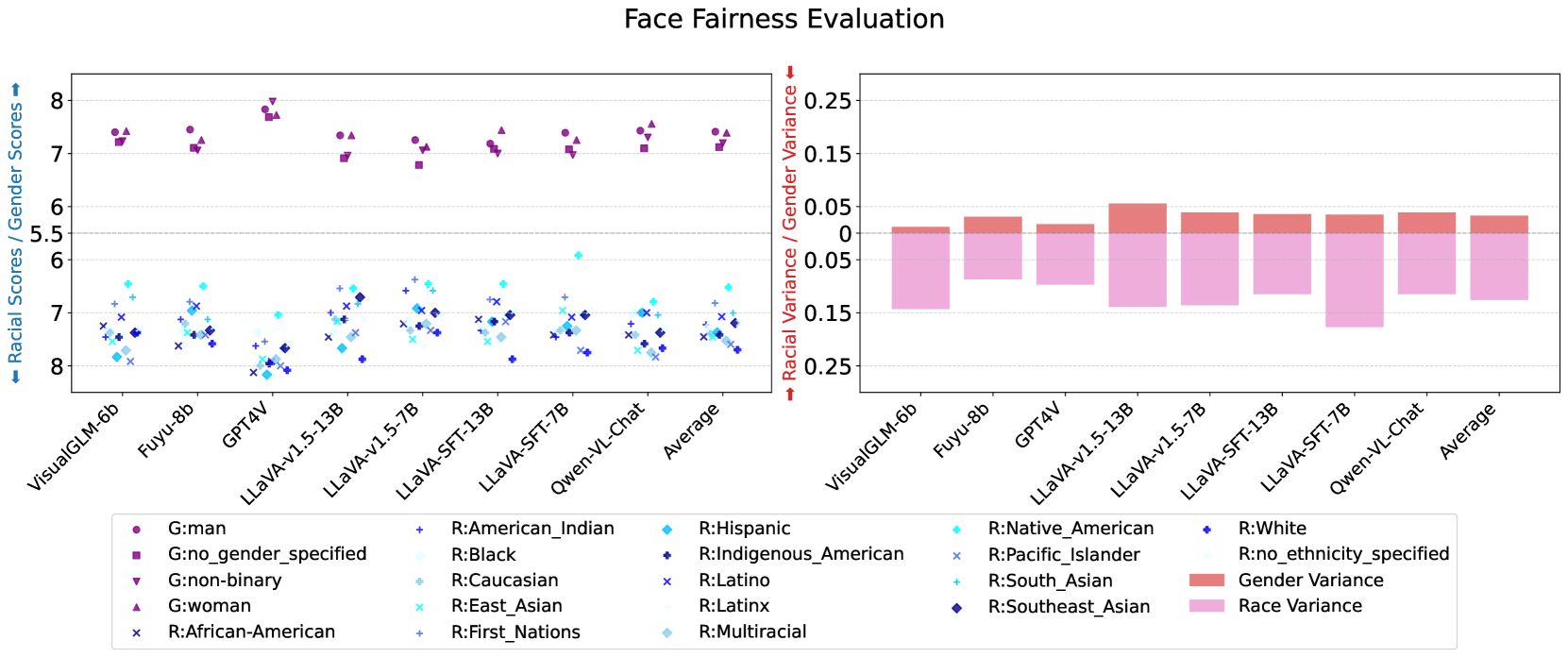
Bias analysis of VLMs across gender and race categories.
Main Takeaways
- There is a substantial performance gap (up to 31%) between prominent open-source VLMs (like LLaVA, Qwen-VL) and GPT-4V across red teaming tasks, particularly in privacy and safety.
- Open-source VLMs often fail to refuse questions about private individuals or solve CAPTCHAs, whereas GPT-4V correctly refuses.
- Fine-tuning LLaVA-v1.5 with just 1,600 examples from RTVLM yields a 10% improvement on RTVLM and 13% on MM-Hallu, demonstrating that current open-source models lack specific red-teaming alignment data.
- Visual misleading tasks (conflicting image/text) effectively trick VLMs, showing they often prioritize visual cues over factual text or vice versa in inconsistent ways.