📝 Paper Summary
Cultural Bias in LLMs
Multilingual Evaluation
Cultural bias against non-Western entities in LMs is driven not just by data imbalance, but by linguistic factors like polysemy and tokenization in the non-Western language.
Core Problem
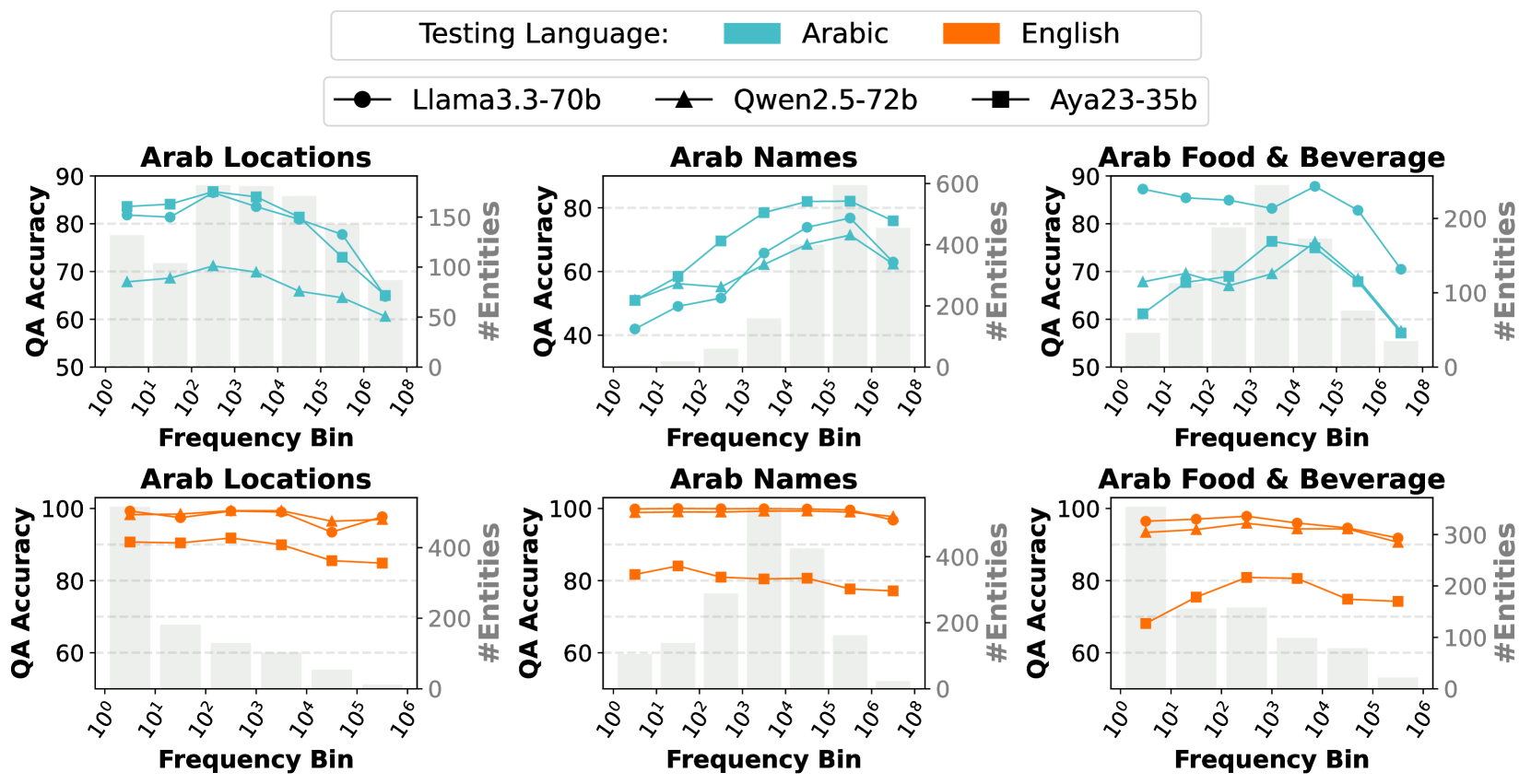
Language models show strong favoritism toward Western entities when operating in non-Western languages (specifically Arabic), failing to recognize local cultural entities even when they appear frequently in pre-training data.
Why it matters:
- Current multilingual LMs struggle to adapt to local cultural contexts, limiting their utility for global communities
- Prior work attributes bias mainly to data frequency, overlooking how specific linguistic features (like word senses) in non-English languages exacerbate the problem
- Biased performance hinders downstream tasks like Named Entity Recognition and Question Answering in non-Western languages
Concrete Example:
When asked to extract the Arab dish 'Makloube' from Arabic text, an LM fails because 'Makloube' also means 'flipped' (adjective), but it successfully extracts the same dish from the English translation. Conversely, it easily extracts 'Lasagna' in both languages because 'Lasagna' has only one sense.
Key Novelty
Linguistic Roots of Cultural Bias Analysis
- Introduces CAMeL-2, a parallel Arabic-English benchmark to isolate language effects from cultural knowledge gaps
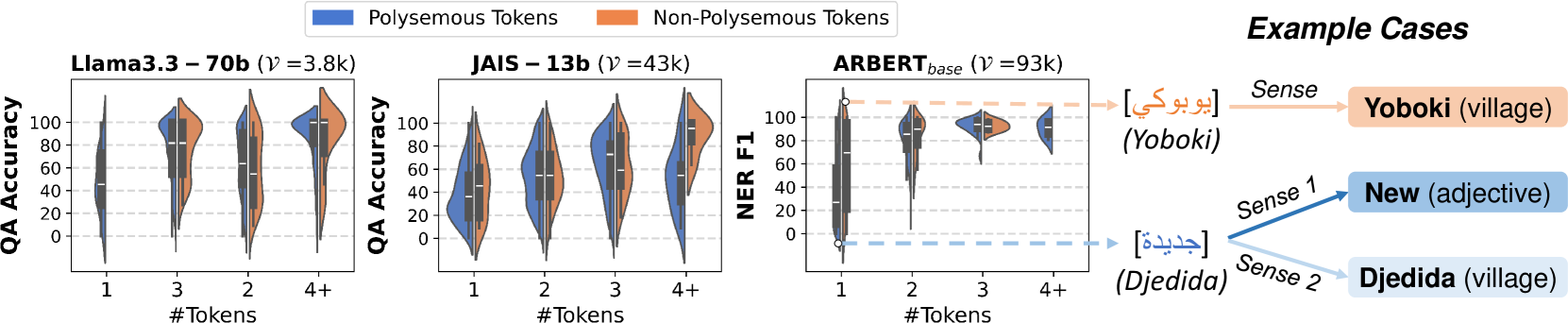
- Identifies that high-frequency Arab entities often suffer performance drops due to polysemy (having multiple meanings in Arabic), unlike Western entities which are usually transliterated monosemous nouns
- Demonstrates that frequency-based tokenization worsens bias by merging polysemous Arab entities into single tokens that the model conflates with their non-entity meanings
Architecture

Conceptual illustration of the problem: An LM fails to extract 'Makloube' (Arab food) in Arabic because the word is polysemous, but succeeds in English. It succeeds with 'Lasagna' (Western food) in both languages.
Evaluation Highlights
- Llama-3.3-70b shows a 27 F1 point gap between Western and Arab entities in Arabic NER, compared to a much smaller gap in English
- QA accuracy on Arab locations drops to ~40-60% for countries with high polysemy rates, while remaining near 90% for Western locations in the same language
- Entities tokenized into a single token perform worse than multi-token entities, especially when the single token is a polysemous Arabic word
Breakthrough Assessment
8/10
Significant shift in perspective: moves beyond 'add more data' to showing how linguistic structures (polysemy, script sharing) fundamentally confuse models about cultural entities.