📝 Paper Summary
GUI Agents
Multimodal Reinforcement Learning
UI-AGILE enhances GUI agents by training with continuous distance-based rewards and length-constrained reasoning, while using a tile-based inference strategy to handle high-resolution visual noise.
Core Problem
GUI agents struggle with a reasoning dilemma (thinking hurts grounding/latency vs. no-thinking hurts planning), ineffective binary rewards that fail to teach precise clicking, and visual noise on high-resolution screens.
Why it matters:
- Elaborate reasoning processes often degrade grounding accuracy and increase latency, making agents slow and less precise
- Simple binary rewards (success/fail) provide sparse feedback on complex tasks and do not incentivize clicking the semantic center of an element
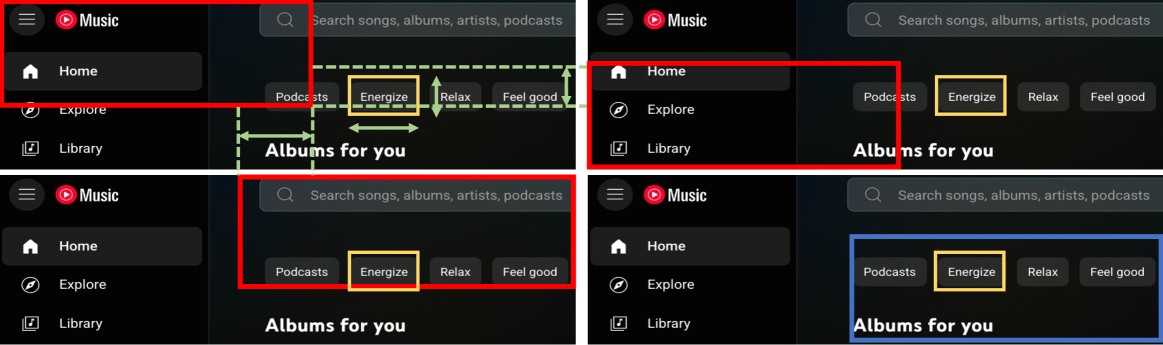
- High-resolution displays (e.g., 4K) generate excessive visual tokens, overwhelming models with irrelevant background noise
Concrete Example:
On a 3840x2160 screen, converting the image to tokens results in over 10,000 tokens, mostly irrelevant background. A standard agent processing this full image fails to locate a small button due to noise. In preliminary tests, simply cropping the image to 1024x1024 improved UGround-V1-7B's accuracy from 31.6 to 56.0.
Key Novelty
UI-AGILE (Training & Inference Framework)
- **Simple Thinking (Training):** A reward function that encourages reasoning chains of moderate length—penalizing both 'under-thinking' and 'over-thinking'—to balance planning capability with grounding accuracy.
- **Continuous Grounding Reward (Training):** Replaces binary success/fail rewards with a continuous score based on the Chebyshev distance to the target center, incentivizing precise localization.
- **Decomposed Grounding (Inference):** Splits high-resolution screens into sub-images to reduce noise, generates candidates per sub-image, and uses a VLM to select the best match via a Yes/No Q&A process.
Architecture
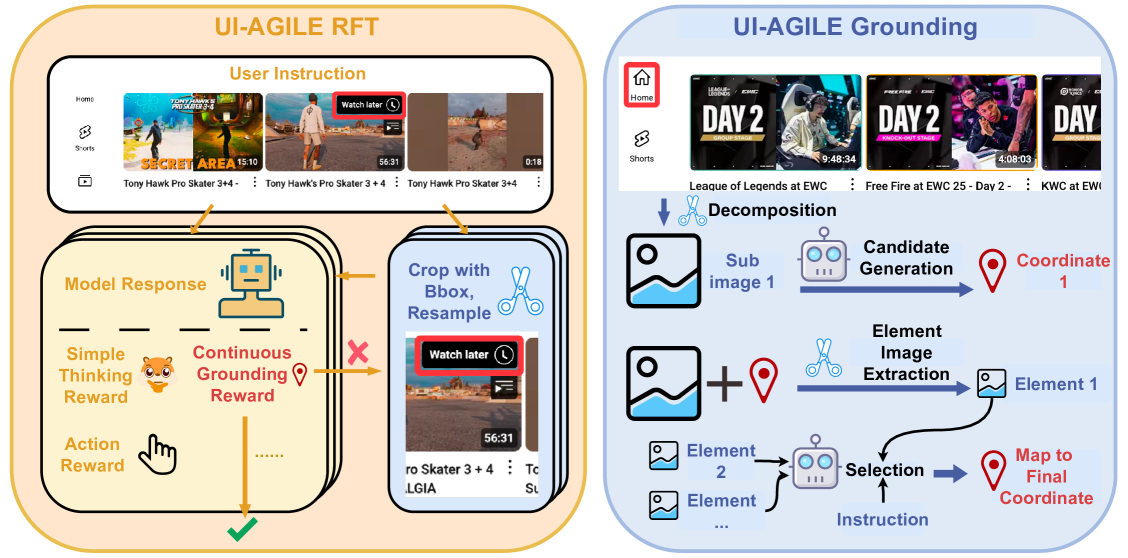
Overview of the UI-AGILE framework covering both Training (left) and Inference (right) stages.
Evaluation Highlights
- Achieves 23% grounding accuracy improvement over the best baseline on the ScreenSpot-Pro benchmark when using both training and inference enhancements
- Preliminary controlled experiments show that reducing visual noise via cropping improves UGround-V1-7B accuracy from 31.6 to 56.0 (+24.4 points)
- Efficient training requiring only ~9,000 samples and 2 epochs to achieve superior performance
Breakthrough Assessment
8/10
Addresses critical bottlenecks in GUI agents (visual noise on 4K screens and sparse rewards) with practical, effective solutions. The inference decomposition strategy is a plug-and-play enhancement applicable to existing models.