📝 Paper Summary
Multimodal Large Language Models (MLLMs)
Chain-of-Thought (CoT) Reasoning
Tool-augmented Reasoning
Simple o3 emulates the 'thinking with images' paradigm by integrating dynamic visual tools into an interleaved vision-language reasoning chain, trained on a synthesized dataset of 146K diverse samples.
Core Problem
Existing MLLMs lack extended Chain-of-Thought capabilities in multimodal scenarios, specifically the ability to iteratively manipulate and revisit visual information during reasoning.
Why it matters:
- Current approaches separate perception from reasoning, limiting performance on complex tasks requiring hierarchical decomposition.
- Eliciting tool-use often relies on resource-intensive Reinforcement Learning or human annotation, lacking scalable data synthesis pipelines.
- The impact of specific visual tools and input resolution on interleaved reasoning remains underexplored.
Concrete Example:
When answering a question about a small detail in a high-resolution image, standard models might miss the entity due to fixed resolution. Simple o3 uses 'focus_area' to crop the relevant region, creating a new visual token that grounds the reasoning, eventually leading to the correct answer.
Key Novelty
End-to-end framework for 'thinking with images' via tool interaction
- Reproduces OpenAI's o3 paradigm using a scalable 'observe-reason-act' data synthesis pipeline that generates interleaved image-text reasoning chains.
- Integrates dynamic visual tools (focus_area, zoom_in, reuse) directly into the reasoning process, allowing the model to modify its visual input iteratively.
- Employs a modality-aware masking strategy during training to optimize text generation while maintaining cross-modal context from intermediate visual states.
Architecture
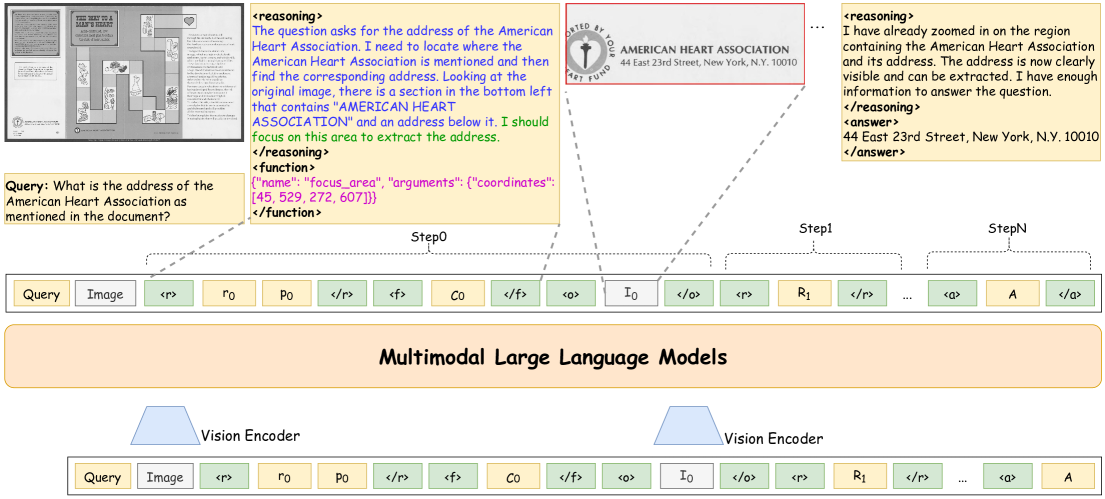
The inference workflow of Simple o3 showing the iterative loop of reasoning, tool execution, and observation update.
Evaluation Highlights
- +31.2 point improvement on the MME reasoning subset compared to the base Qwen2.5-VL-7B model, surpassing GPT-4o by 27 points.
- Achieves 7.4% and 12.9% improvements on fine-grained perception benchmarks HR-Bench 4K and VStarBench respectively.
- +16.6% improvement on MMVet spatial reasoning subtasks, demonstrating enhanced understanding of object relationships.
Breakthrough Assessment
8/10
Significantly advances open-source multimodal reasoning by successfully replicating the 'thinking with images' paradigm with a scalable data pipeline, showing massive gains on reasoning benchmarks.