📝 Paper Summary
Chain-of-Thought (CoT) Reasoning
Model Distillation
Efficient Inference
QFFT fine-tunes language models exclusively on reasoning responses without input questions, preserving efficient short reasoning patterns while enabling reflective long reasoning only when errors or uncertainty arise.
Core Problem
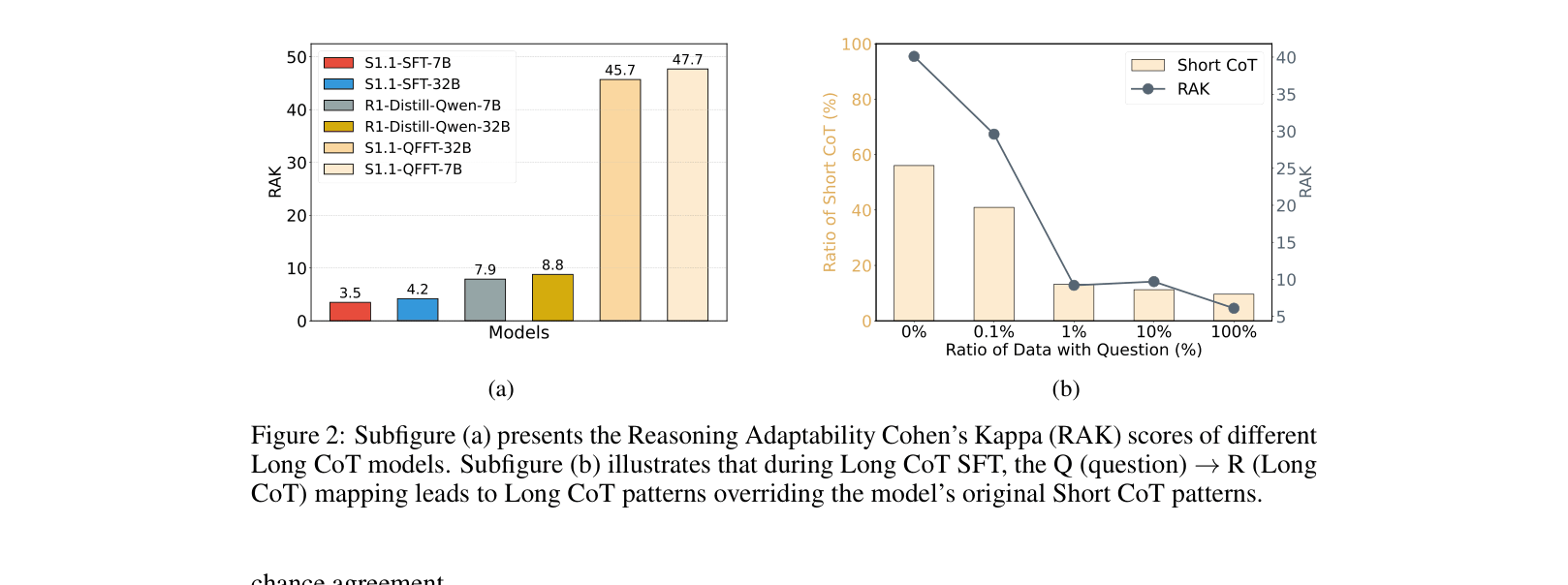
Distilling Long Chain-of-Thought (CoT) capabilities into smaller models via Supervised Fine-Tuning (SFT) causes 'overthinking,' where models indiscriminately apply lengthy, redundant reasoning even to simple problems.
Why it matters:
- Standard SFT overrides a model's efficient 'Short CoT' capabilities, increasing inference latency and cost by generating unnecessary tokens
- Current methods force a fixed mapping from Questions to Long Responses, losing the ability to adapt reasoning length to problem difficulty
- Existing Long-to-Short compression methods often require substantial additional training or degrade performance on complex tasks
Concrete Example:
When solving a simple math problem (e.g., calculating walking time), a standard SFT model distilled from DeepSeek-R1 generates 1,646 tokens of redundant checks. In contrast, the QFFT model solves it in 415 tokens using Short CoT, but correctly triggers lengthy verification (starting with 'Wait...') only when it encounters a non-integer root in a complex step.
Key Novelty
Question-Free Fine-Tuning (QFFT)
- Removes the input question from the training data, fine-tuning the model using *only* the Long CoT response sequences
- Prevents the model from learning a rigid Question-to-LongResponse mapping, thereby preserving its default Short CoT behavior for simple inputs
- Implicitly teaches the model to trigger reflective Long CoT patterns (like self-correction) only when internal uncertainty arises during generation
Architecture

A case study illustrating the adaptive reasoning flow of a QFFT model.
Evaluation Highlights
- Reduces average response length by ~50% across GSM8K, MATH, and AIME datasets compared to standard SFT while maintaining comparable accuracy
- Achieves 78.6% accuracy on MATH with completely irrelevant/noisy input questions (Level IV noise), whereas standard SFT collapses to 0.4%
- Outperforms SFT by +8.7 points on MMLU-Pro (Out-of-Domain) with Qwen2.5-32B-Instruct, demonstrating superior generalization
Breakthrough Assessment
8/10
Simple yet highly effective intervention (removing questions) that solves the prevalent 'overthinking' problem in reasoning distillation, offering massive efficiency gains with robust performance.