📝 Paper Summary
Knowledge Graph (KG) based Dialogue Generation
Automated Benchmark Construction
Chatty-Gen is an automated, KG-agnostic platform that uses a multi-stage retrieval-augmented generation pipeline with assertion-based validation to create domain-specific dialogue benchmarks from arbitrary Knowledge Graphs.
Core Problem
Existing methods for creating dialogue benchmarks are either labor-intensive (manual), template-restricted (brittle for new KGs), or prone to LLM hallucinations when generating complex dialogues with corresponding SPARQL queries.
Why it matters:
- Evaluating chatbots in specific domains requires high-quality, structured benchmarks which are currently expensive to produce.
- Manual creation is not scalable; template-based systems require redesign for every new KG.
- Direct LLM generation often fails to produce factually grounded dialogues or correct SPARQL queries (hallucinations).
Concrete Example:
A standard LLM might generate a question like 'What is his nationality?' without prior context, or hallucinate facts not present in the KG. Existing rule-based systems like Maestro generate rigid QA pairs where every answer is the seed entity, failing to form a coherent conversational flow.
Key Novelty
Multi-stage RAG with Assertion-based Automatic Validation
- Decomposes the complex task of dialogue generation into manageable stages (context extraction, summarization, question generation, answer generation, dialogue formation).
- Introduces assertion rules between stages to automatically validate intermediate outputs (e.g., checking if a generated question matches a KG triple) before proceeding, mitigating error propagation.
- Uses a popularity-based subgraph retrieval method to select representative seed entities and diverse contexts without processing the entire KG.
Architecture
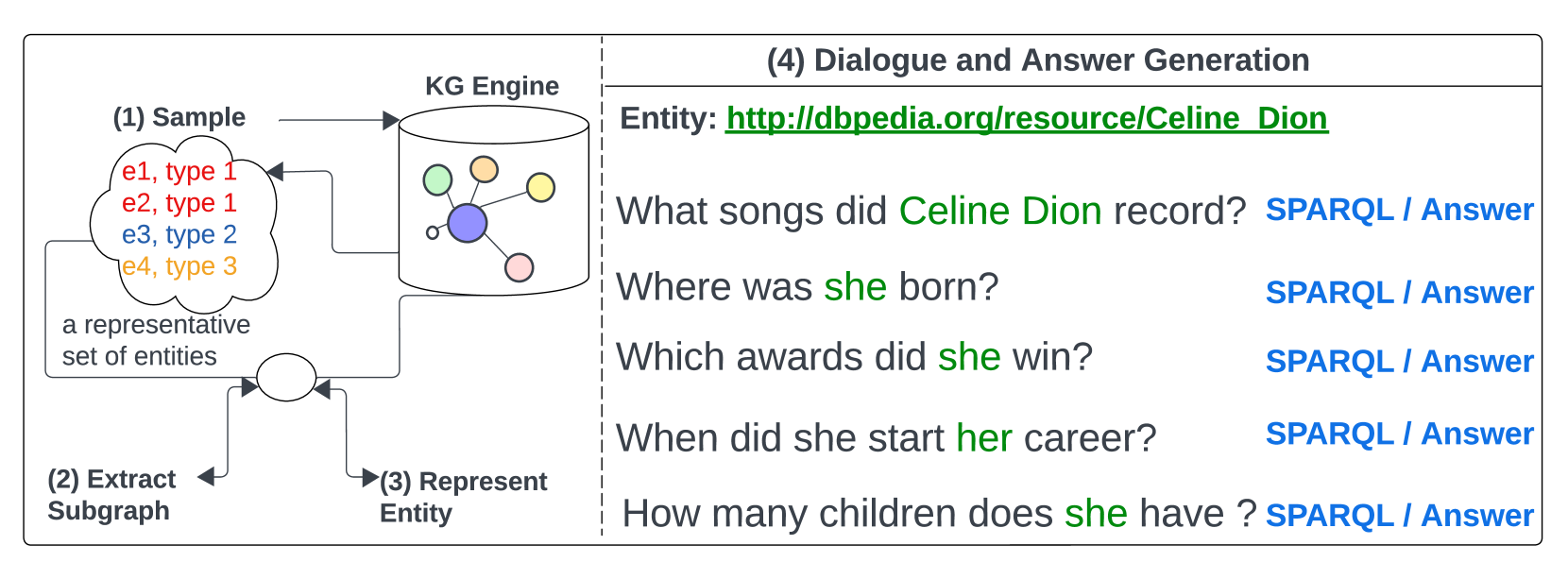
The logical steps of generating a dialogue from a Knowledge Graph, illustrating the transition from entity sampling to dialogue formation.
Evaluation Highlights
- Reduces benchmark generation time for large KGs (e.g., DBpedia) by 99% compared to the state-of-the-art system Maestro (10 minutes vs. 30 hours).
- Achieves high success rates (98-100%) in generating valid dialogues across multiple LLMs (GPT-4o, Llama-3, Mistral), whereas baselines often fail.
- Chatty-Gen with open-source models (Llama-3/CodeLlama) achieves quality and success rates comparable to using GPT-4o alone, demonstrating cost-effectiveness.
Breakthrough Assessment
8/10
Significantly automates a traditionally manual or brittle process. The 99% time reduction and ability to use open-source models to match GPT-4 performance make it a highly practical tool for KG researchers.