📝 Paper Summary
Medical Large Language Models
Chinese Medical NLP
Dialogue Systems
Zhongjing is a Chinese medical LLM trained via a complete pipeline (pre-training, SFT, RLHF) on a new real-world multi-turn dataset to enable proactive doctor-like inquiries and safety alignment.
Core Problem
Existing Chinese medical LLMs rely heavily on Supervised Fine-Tuning (SFT) with single-turn or distilled data, leading to rote memorization, lack of proactive inquiry, and misalignment with expert intent.
Why it matters:
- Authentic medical diagnosis requires multi-turn interaction where doctors proactively ask questions to clarify conditions, which single-turn models cannot simulate
- Over-reliance on SFT causes models to be overconfident and hallucinate, lacking the safety and 'don't know' awareness crucial for patient safety
- Distilled data (from GPT) mimics speech patterns but may lead to a collapse of substantive inherent capabilities compared to learning from real expert data
Concrete Example:
In a real scenario, if a patient says 'I have a headache', a real doctor asks 'How long?' or 'Is it throbbing?'. Current SFT models might immediately prescribe medicine based on the single input, missing critical diagnostic context.
Key Novelty
Full-Pipeline Training with Real-World Multi-turn Data (Zhongjing)
- Implements the first complete training pipeline for a Chinese Medical LLM: Continuous Pre-training (knowledge) → SFT (dialogue capability) → RLHF (alignment and safety)
- Constructs CMtMedQA, a large-scale dataset sourced from real doctor-patient dialogues that preserves the doctor's proactive inquiry behavior, unlike distilled datasets
- Uses a medical-specific RLHF process with refined annotation rules covering safety, professionalism, and fluency to align the model with human experts
Architecture
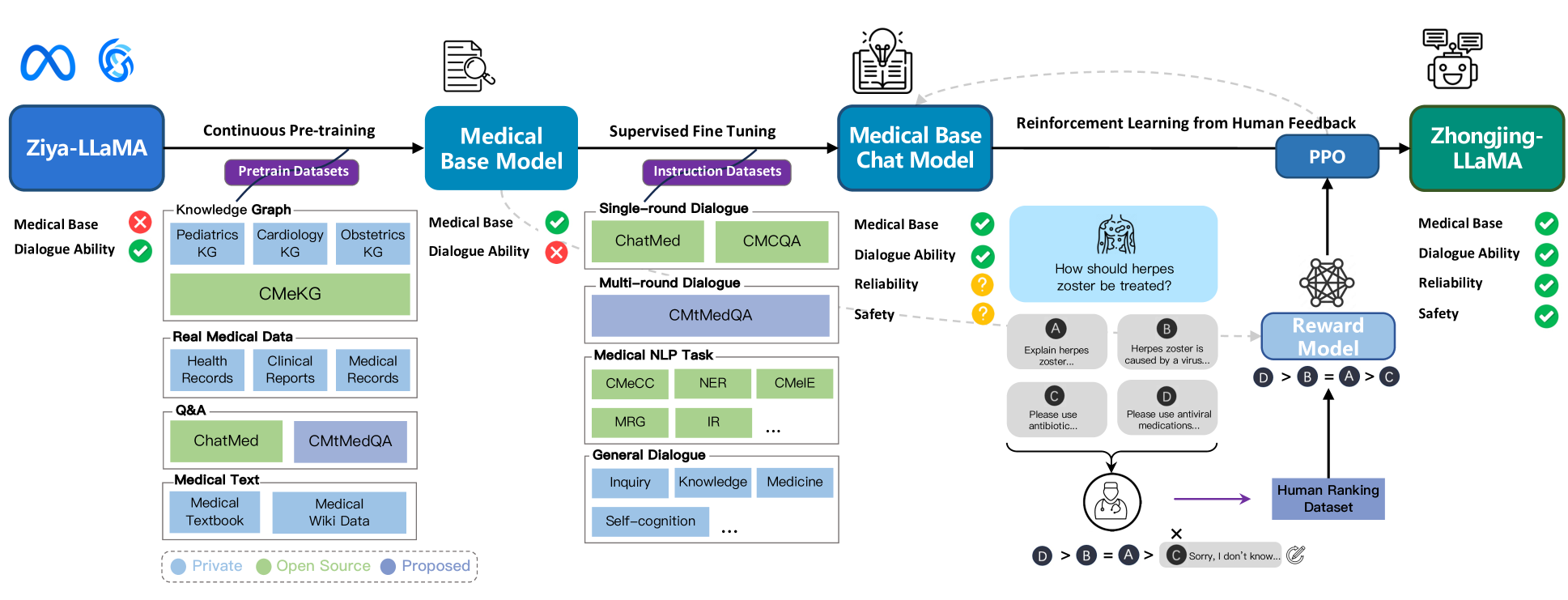
The three-stage training pipeline of Zhongjing: (1) Continuous Pre-training on medical corpus, (2) Supervised Fine-Tuning (SFT) on various instruction data, and (3) RLHF utilizing a reward model trained on expert rankings.
Evaluation Highlights
- Constructed CMtMedQA dataset with 70,000 authentic multi-turn doctor-patient dialogues across 14 medical departments
- Matches the performance of ChatGPT in some specific medical abilities despite having only ~1% of the parameters (13B vs estimated larger size)
- Significantly enhances capability for proactive inquiry initiation compared to SFT-only baselines
Breakthrough Assessment
7/10
Significant for implementing the full RLHF pipeline in the specific domain of Chinese medicine and releasing a high-quality real-world multi-turn dataset, moving beyond simple SFT approaches.