📝 Paper Summary
Robotics Foundation Models
Reinforcement Learning for Robotics
Self-Improving Systems
This paper enables robots to teach themselves new skills by first learning to predict how close they are to a goal, then using that prediction as a reward signal to practice without human help.
Core Problem
Training robots currently relies heavily on imitating humans (behavioral cloning), which requires massive amounts of expensive demonstration data and limits robots to only copying what they have seen.
Why it matters:
- Imitation learning is data-inefficient; slight improvements require exponentially more human demonstrations
- Manually designing reward functions for every possible robot task in the real world is impossible (untenable engineering effort)
- Current methods struggle to generalize behaviors to new skills beyond the exact scenarios in the training data
Concrete Example:
In the LanguageTable task, simply increasing human imitation data by 8x only improves success from 45% to 60%. The robot struggles to adjust when it fails or encounters a scenario slightly different from the human demos.
Key Novelty
Two-Stage Self-Improvement via Steps-to-Go
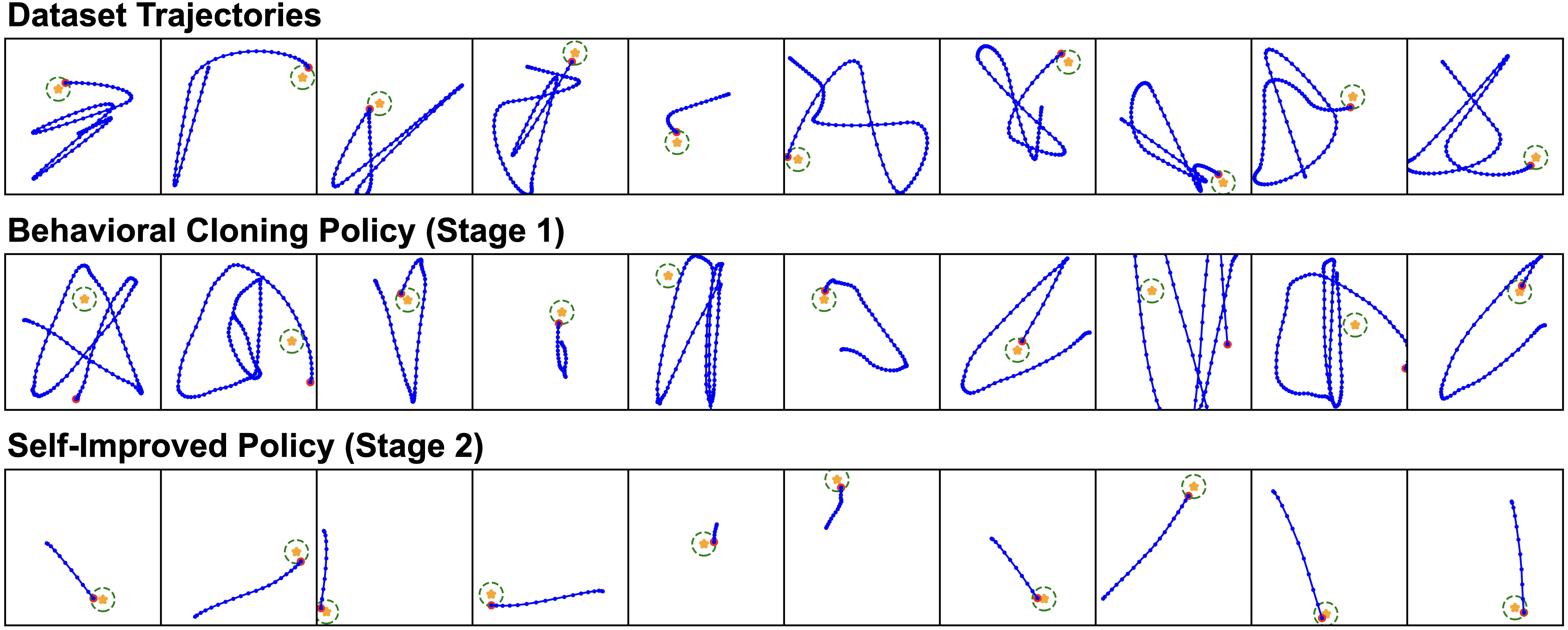
- Stage 1 (Supervised): The robot learns to copy human actions AND predict how many steps remain until the goal is reached (steps-to-go)
- Stage 2 (Self-Improvement): The robot uses its own 'steps-to-go' prediction as a reward signal. If an action reduces the estimated steps remaining, it gets a positive reward, allowing it to practice autonomously.
Architecture
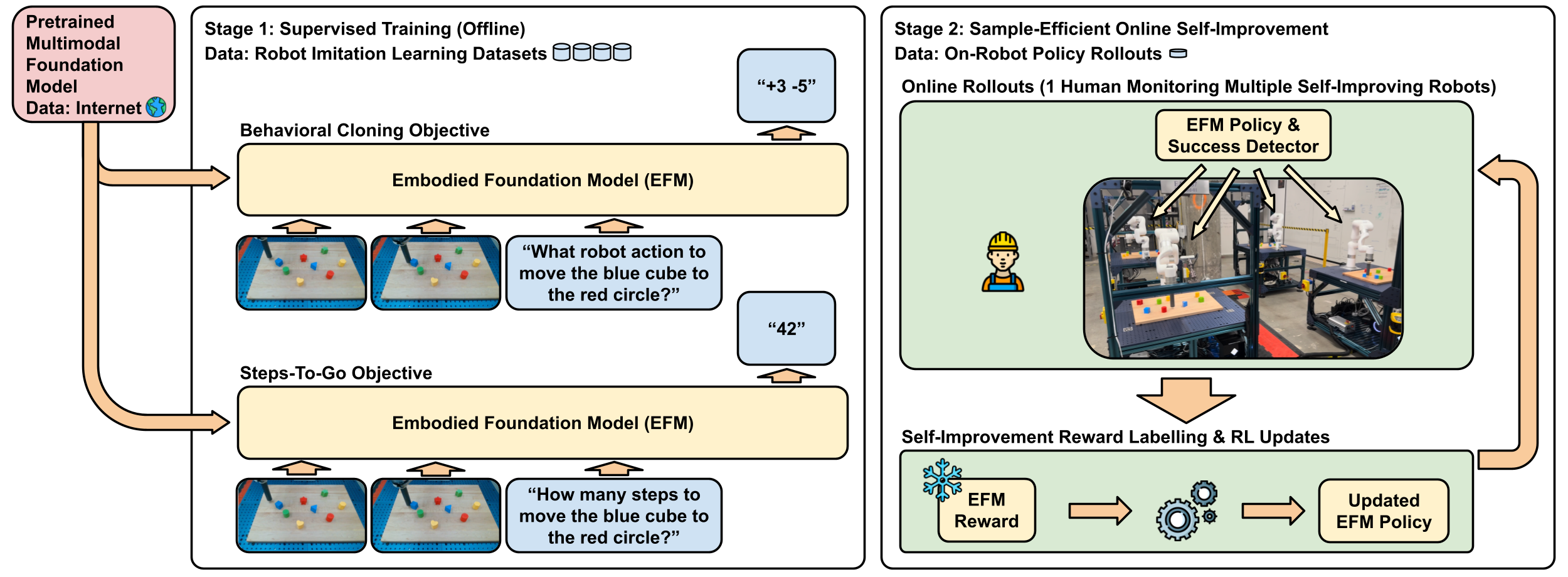
Pseudocode for the Stage 2 Self-Improvement loop.
Evaluation Highlights
- Self-Improvement with just 10% additional autonomous practice improves success rates from 45% to 75% on real-world LanguageTable, compared to 8x more human data yielding only 60%
- Achieves ~87-88% success rate on real-world LanguageTable tasks using only 20% of the original imitation dataset plus self-improvement
- Demonstrates ability to acquire novel skills not present in the imitation data, generalizing beyond semantic changes to behavioral changes
Breakthrough Assessment
9/10
Significantly outperforms scaling human data (the dominant paradigm) by using autonomous self-improvement. Solves the reward engineering bottleneck by learning rewards from data, enabling scalable real-world robot learning.