📝 Paper Summary
Medical Visual Question Answering (Med-VQA)
Large Reasoning Models (LRMs)
MedVLThinker demonstrates that Reinforcement Learning with Verifiable Rewards (RLVR) on filtered text-only medical data significantly outperforms supervised fine-tuning and multimodal training for medical visual reasoning tasks.
Core Problem
Current medical Large Multimodal Models (LMMs) lack open, reproducible recipes for reasoning capabilities, often relying on closed data or failing to integrate 'thinking' paradigms effectively with multimodal inputs.
Why it matters:
- The absence of open recipes hinders community research and fair comparison in medical AI
- Clinicians need models that can 'think before answering' to handle complex multimodal diagnoses reliability
- Existing approaches are either closed-source, limited to specific modalities (e.g., MRI only), or release weights without training code
Concrete Example:
When trained via standard Supervised Fine-Tuning (SFT) on reasoning traces, the model's performance actually degrades compared to the base model (e.g., accuracy drops from 53.5% to 43.8%), showing that naive imitation of reasoning chains is ineffective compared to RL-based self-reasoning.
Key Novelty
RLVR-centric Open Recipe for Medical LMMs
- Applies Reinforcement Learning with Verifiable Rewards (RLVR) using Group Relative Policy Optimization (GRPO) to medical visual QA, rewarding correct final answers rather than imitating reasoning traces
- Implements a rigorous difficulty-based data filtering pipeline ('pass count' filtering) to remove trivial or impossible questions before training
- Discovering that training on text-only reasoning data with RL provides larger gains for *multimodal* tasks than training on multimodal data itself
Architecture
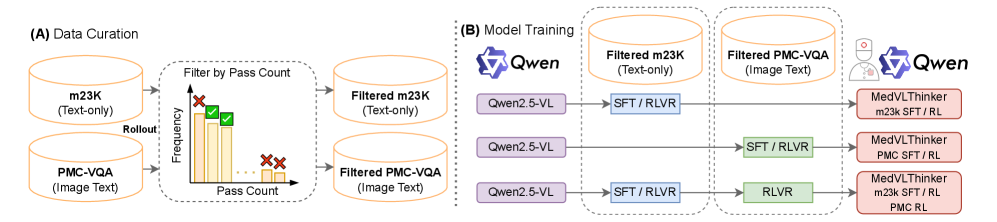
The complete MedVLThinker pipeline including data curation, difficulty filtering, and the two training paradigms (SFT vs RLVR)
Evaluation Highlights
- MedVLThinker-7B (RLVR on text-only data) achieves 54.9% average accuracy across 6 benchmarks, setting a new state-of-the-art for open medical LMMs
- RLVR on text-only data improves the 7B base model from 53.5% to 54.9%, while SFT on text-only data degrades it to 43.8%
- Scaling the approach to 32B parameters achieves performance on par with the proprietary GPT-4o model
Breakthrough Assessment
8/10
Provides the first fully open recipe for reasoning medical LMMs and reveals the counter-intuitive finding that text-only RLVR beats multimodal training for visual tasks. Strong empirical results matching GPT-4o.