📝 Paper Summary
Multi-Modal Large Language Models (MLLMs)
Human Preference Alignment
OmniAlign-V enhances multi-modal alignment by training models on a rigorously filtered, semantically rich dataset of 200K open-ended questions, bridging the gap between foundational capabilities and human preferences.
Core Problem
Open-source MLLMs excel at basic tasks (OCR, detection) but fail to align with human preferences in open-ended conversations, often producing short, unhelpful, or hallucinatory responses.
Why it matters:
- Mixing high-quality text-only alignment data into MLLM training fails to improve multi-modal alignment and actively degrades foundational visual skills
- Existing visual instruction datasets focus on short, factual QA, lacking the complexity, creativity, and length required for satisfying human-AI interaction
- Current benchmarks prioritize objective accuracy over subjective helpfulness and user preference
Concrete Example:
When asked an open-ended question about an image, a standard MLLM might give a brief, robotic description. In contrast, preliminary studies showed that while adding text-only alignment data improved text responses, it caused performance drops on visual benchmarks like MMMU (e.g., -1.2 points) and failed to improve visual alignment scores.
Key Novelty
Semantic Richness Filtering & Hybrid Task Taxonomy
- Filters natural images not just by complexity (pixel randomness) but by semantic richness (object detection counts), rejecting chaotic but empty images (e.g., a field of identical tents)
- Splits data generation into distinct pipelines for Natural images (Knowledge, Creative, Inferential) and Infographics (Charts, Posters), applying specialized refinement strategies like merging OCR results with LLM reasoning
Architecture
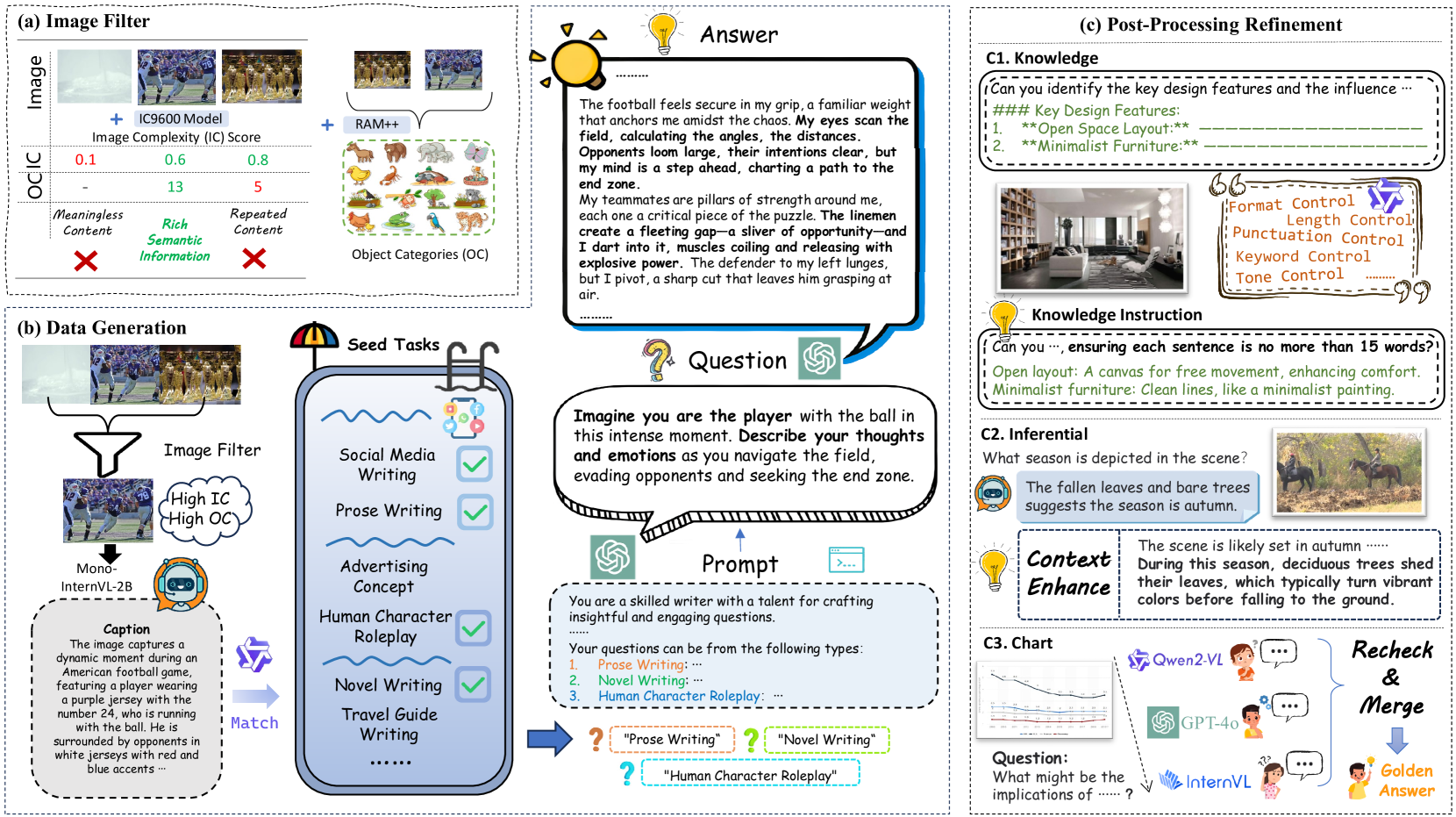
The data synthesis pipeline for OmniAlign-V, detailing image selection and Question-Answer generation/refinement.
Evaluation Highlights
- Achieves 28.5% win-rate on MM-AlignBench with Qwen2.5-32B backbone, outperforming the much larger proprietary-data-tuned Qwen2VL-72B-Instruct (25.1%)
- +13.6 point improvement on WildVision Score (alignment benchmark) when fine-tuning InternLM2.5-7B with OmniAlign-V compared to the LLaVA-Next-778K baseline
- Maintains or improves foundational capabilities, achieving +1.6% on MMMU while simultaneously improving alignment metrics
Breakthrough Assessment
8/10
Strong contribution to data-centric AI for MLLMs. Addresses a critical alignment gap with a reproducible pipeline and high-quality artifacts (dataset + benchmark), showing clear gains over standard baselines.