📝 Paper Summary
Vision-Language-Action (VLA) Models
Robot Manipulation
Reinforcement Learning
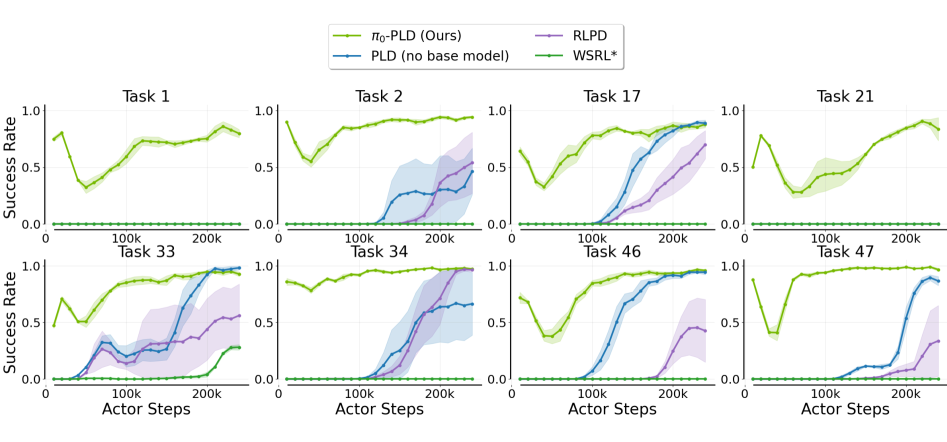
PLD enables VLA models to self-improve by training lightweight residual RL specialists to correct base policy errors, then distilling these policy-aligned recovery trajectories back into the generalist via supervised fine-tuning.
Core Problem
Supervised fine-tuning of VLA models relies on costly human demonstrations that lack 'recovery' behaviors, creating a distribution shift where the model cannot recover from its own execution failures.
Why it matters:
- Human teleoperators instinctively avoid failure states, so their demonstrations do not teach the robot how to recover when it inevitably drifts during deployment
- Collecting high-quality robot data at scale is labor-intensive and expensive compared to language data
- Existing SFT gains are often limited to in-distribution tasks and struggle to generalize to new environments without new human data
Concrete Example:
In a cube pick-up task, a human operator rarely pushes the cube into a corner. When a base policy fails and pushes the cube to a corner, it gets stuck because it has never seen a recovery maneuver from that state. PLD generates specific recovery trajectories for these failure modes.
Key Novelty
Probe, Learn, Distill (PLD)
- Trains lightweight 'residual' RL agents that learn to add corrective actions on top of the frozen base VLA policy, avoiding the instability of fine-tuning the massive VLA directly with RL
- Uses 'Base Policy Probing' for data collection: rollouts start with the base policy to reach likely failure states, then the RL specialist takes over to demonstrate recovery, ensuring data is relevant to the model's actual deployment distribution
Architecture
The PLD pipeline: Stage 1 (Specialist Acquisition via Residual RL), Stage 2 (Data Collection via Probing), Stage 3 (Fine-tuning Generalist)
Evaluation Highlights
- Achieves near-saturated 99% success rate on the LIBERO simulation benchmark, surpassing human-data baselines
- 100% success rate (30/30 trials) on real-world Franka arm tasks (peg insertion, cube pick-up), whereas human-data SFT failed significantly on the pick-up task (10/30)
- Delivers >50% performance gains on the SimplerEnv benchmark compared to base baselines
Breakthrough Assessment
9/10
Demonstrates a scalable 'data flywheel' for robotics that outperforms human data without needing humans in the loop. The method is architecture-agnostic and works on real hardware.