📊 Experiments & Results
Evaluation Setup
Zero-shot evaluation on medical multiple-choice QA benchmarks
Benchmarks:
- MedQA (USMLE-style clinical questions)
- MedMCQA (Indian medical entrance exams)
- PubMedQA (Biomedical research QA)
- MMLU-Pro Medical (Hard expert-level knowledge)
- GPQA Medical (Hard expert-level knowledge)
- MedXpert (Challenging clinical reasoning)
Metrics:
- Accuracy
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Main comparison shows AlphaMed-70B outperforming top closed and open source models on the hardest benchmark. | ||||
| MedXpert | Accuracy | 82.5 | 84.2 | +1.7 |
| MedXpert | Accuracy | 83.1 | 84.2 | +1.1 |
| Comparison at the 8B scale demonstrates superiority over models trained with expensive distilled CoT. | ||||
| MedXpert | Accuracy | 66.5 | 69.7 | +3.2 |
| MedQA | Accuracy | 62.4 | 73.9 | +11.5 |
| Ablation studies reveal that data informativeness (not just size) drives reasoning performance. | ||||
| Average across 6 benchmarks | Accuracy | 58.96 | 55.71 | -3.25 |
Experiment Figures
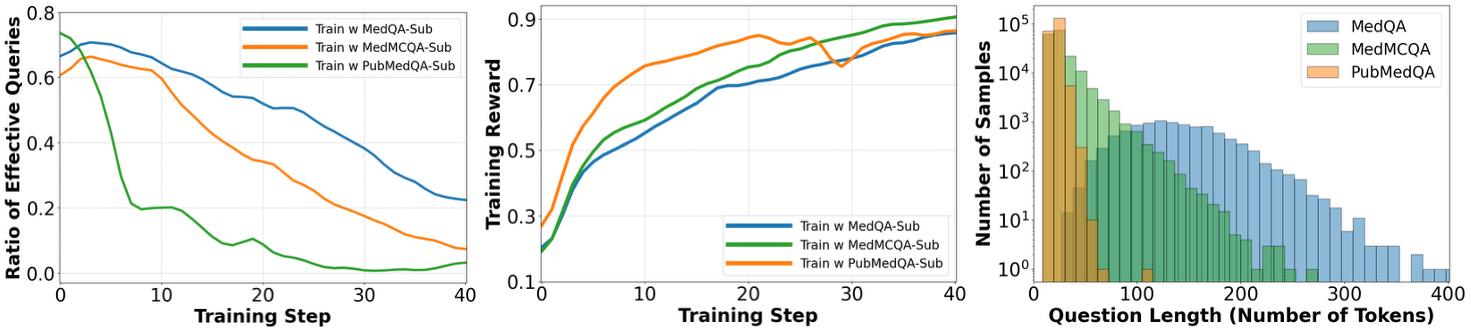
Analysis of training dynamics (effective query ratio and reward) and question length across different dataset subsets.
Main Takeaways
- Minimalist RL is sufficient: Reasoning capabilities can emerge purely from rule-based rewards on final answers, without SFT on reasoning traces.
- Data Informativeness is key: Training on long, complex questions (MedQA) yields far better reasoning than short, noisy ones (PubMedQA), even when dataset size is controlled.
- Difficulty Mix matters: While hard samples benefit hard benchmarks (MedXpert), a mix of easy and medium difficulty samples is essential for robust generalization across all tasks.
- Inverse U-shape trend: For standard benchmarks, training on very hard samples (L5-L6) can yield diminishing returns, whereas for complex benchmarks (MedXpert), harder training data is beneficial.