📝 Paper Summary
Mathematical Reasoning
Post-training (Supervised Fine-Tuning)
Reward Modeling
AceMath improves math reasoning by initializing models with a general-domain SFT stage before math-specific fine-tuning on heavily filtered synthetic data, coupled with a robust reward model.
Core Problem
Existing math-specialized models often lack general reasoning capabilities needed as a foundation for advanced math, and their training data frequently contains incorrectly generated or unsolvable synthetic prompts.
Why it matters:
- Math is a critical testbed for evaluating complex logical reasoning in LLMs, serving as a verifiable proxy for intelligence
- Current approaches that fine-tune directly on math data may miss the benefits of strong general instruction-following capabilities
- Low-quality synthetic data (unsolvable problems, style biases) hampers the reliability of both generation and reward models
Concrete Example:
Synthetic prompt evolution often introduces constraints that make a problem unsolvable (e.g., adding contradictory conditions to a geometry problem). Training on such data, where the model forces an answer to an impossible question, degrades reasoning logic. AceMath explicitly filters these unsolvable synthetic prompts.
Key Novelty
Two-Stage SFT Strategy & Robust Reward Modeling
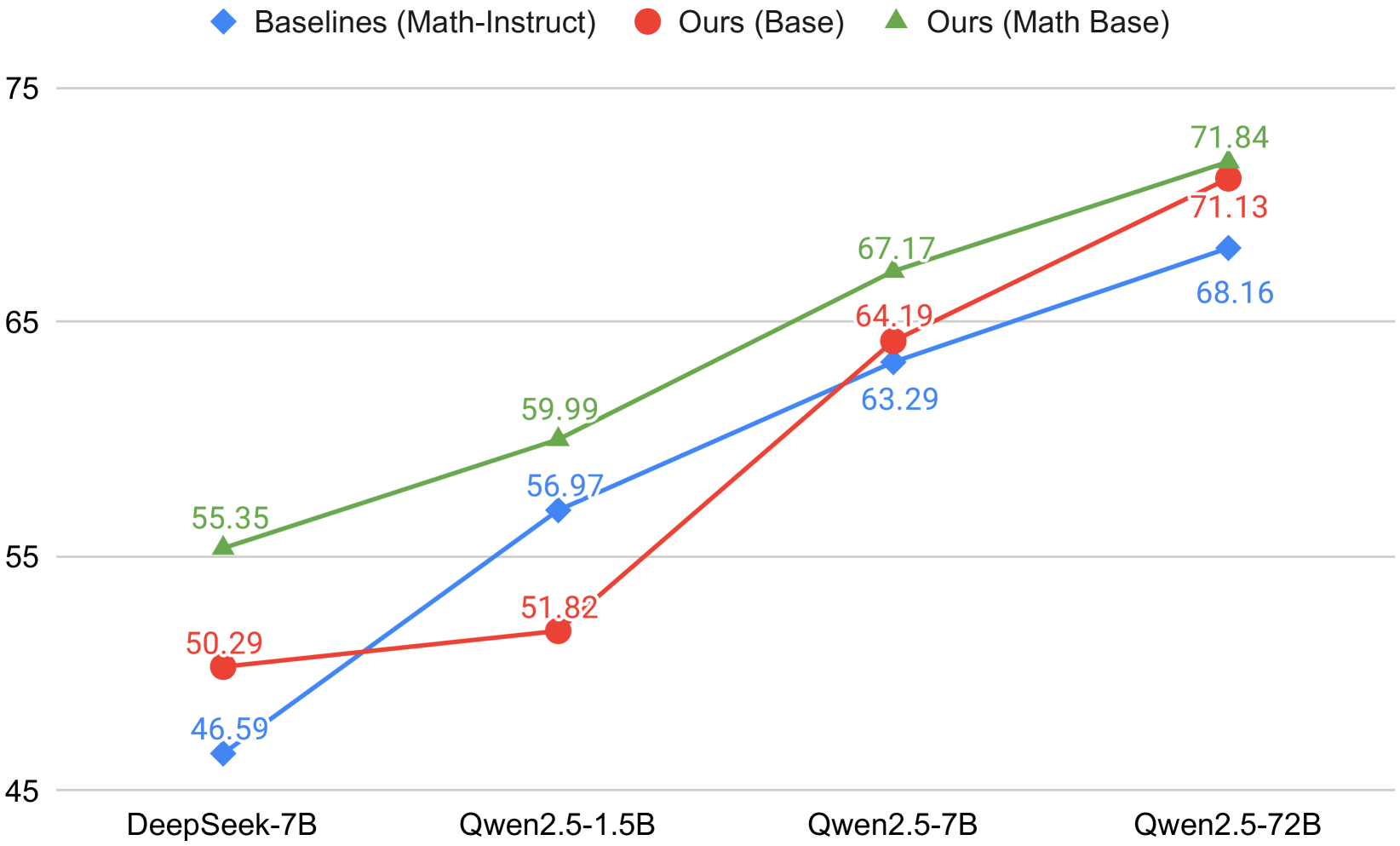
- Implements a 'General SFT' stage first to build instruction-following and coding foundations, creating a better initialization for subsequent 'Math SFT'
- Constructs math SFT data using a rigorous cross-check pipeline where solutions are verified by agreement between two different models (GPT-4o-mini and Qwen2.5-Math)
- Introduces AceMath-RewardBench to evaluate reward models on diverse response styles and difficulty levels
Architecture
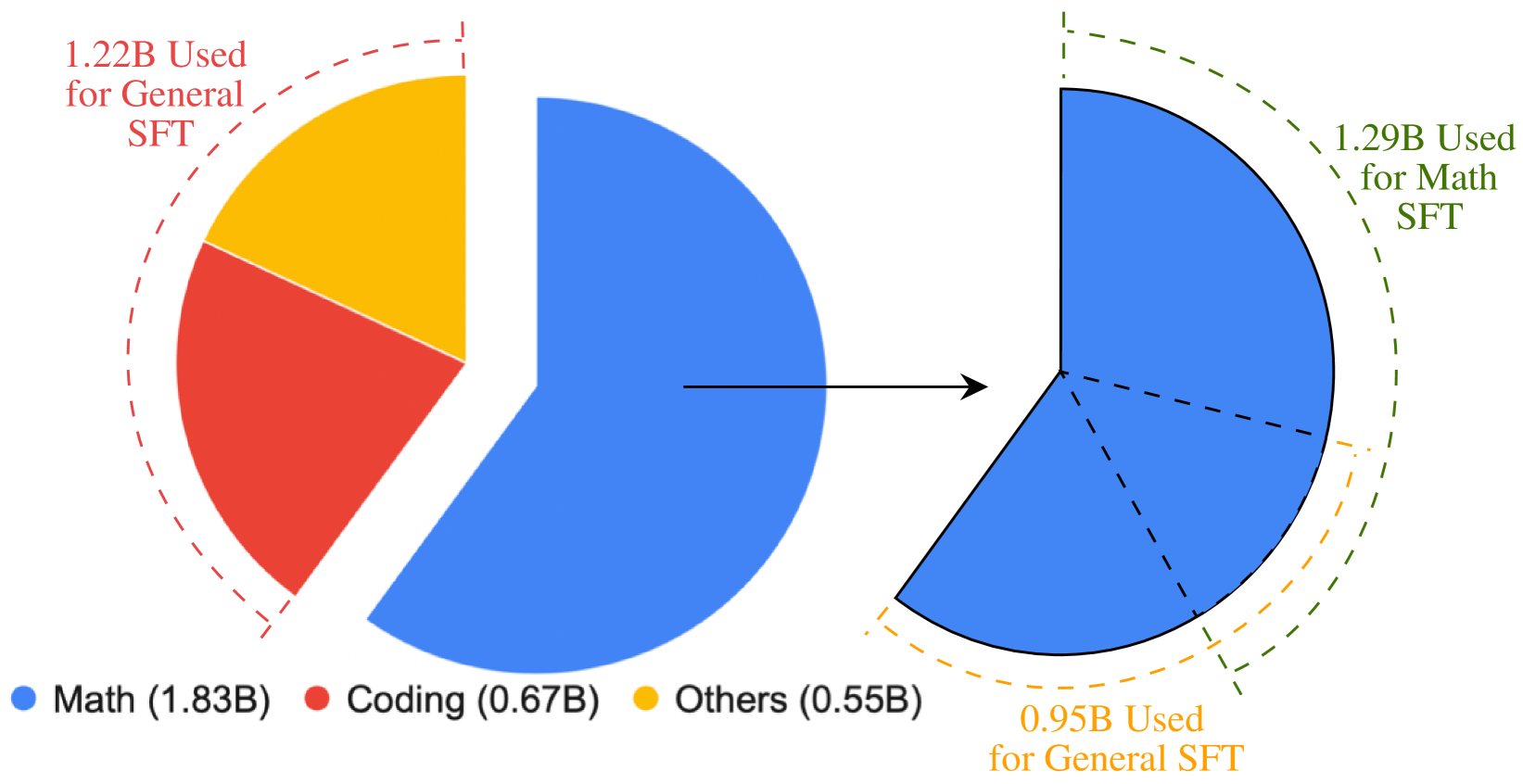
The data curation and training workflow for AceMath, detailing the sources and filtering of General and Math SFT data.
Evaluation Highlights
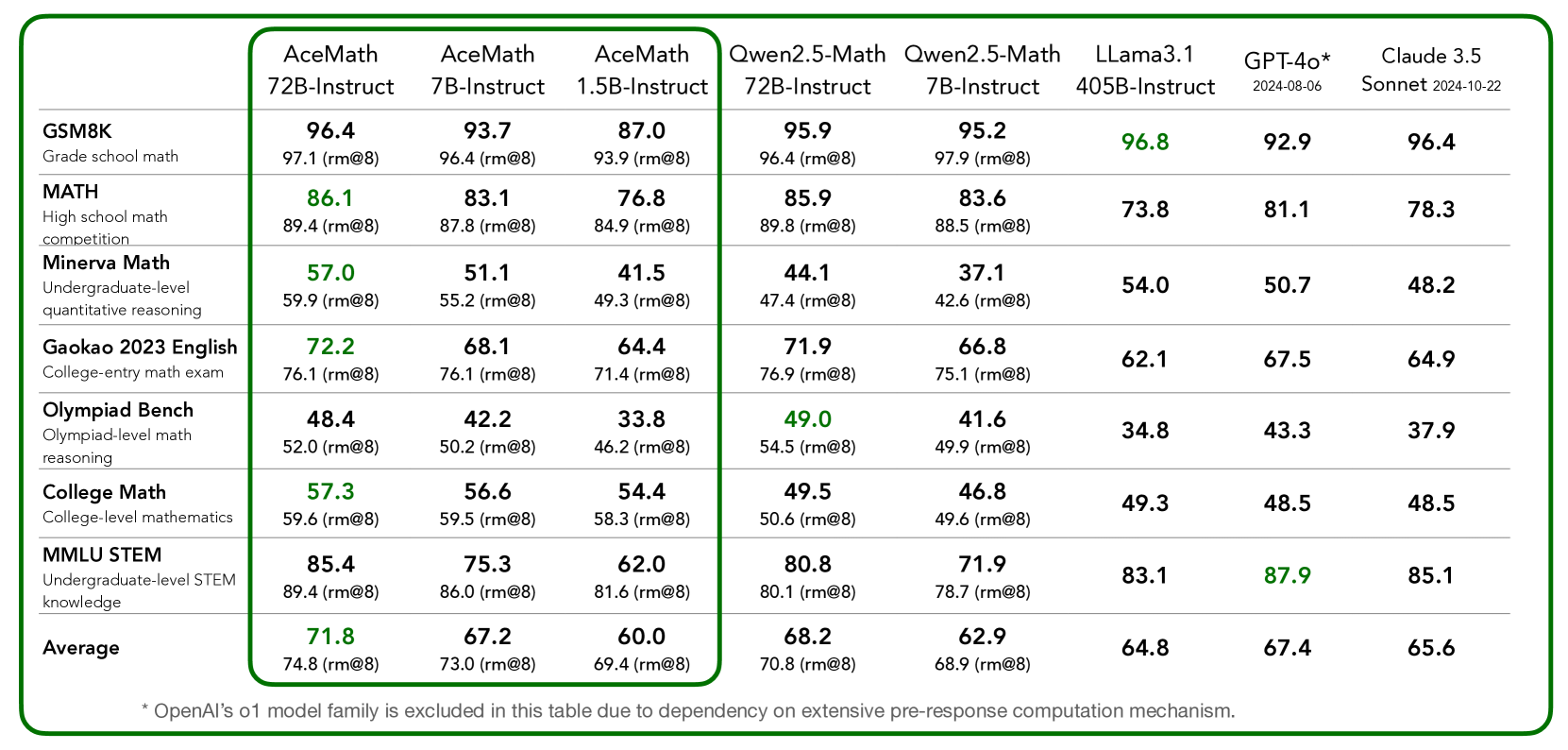
- AceMath-72B-Instruct achieves 71.8 average score across math benchmarks, outperforming Qwen2.5-Math-72B-Instruct (68.2) by 3.6 points
- AceMath-7B-Instruct (67.2) surpasses the baseline Qwen2.5-Math-7B-Instruct (62.9) by 4.3 points and nearly matches the 10x larger Qwen2.5-Math-72B
- Combining AceMath-72B-Instruct with AceMath-72B-RM achieves the highest average rm@8 score across seven math reasoning benchmarks
Breakthrough Assessment
8/10
Significant performance gains over state-of-the-art open-weights models (Qwen2.5-Math) using purely data-centric and post-training innovations. The release of a specialized reward benchmark is also a valuable contribution.