📝 Paper Summary
Instruction Tuning
Data Selection
GRAPE improves supervised fine-tuning by selecting training responses that have the highest length-normalized probability under the base model, ensuring data aligns with the model's pre-trained knowledge.
Core Problem
Standard instruction tuning often pairs prompts with responses from much stronger models (e.g., GPT-4) that are out-of-distribution for the target base model.
Why it matters:
- Training on data that deviates significantly from the base model's distribution can cause diminishing returns or performance degradation despite scaling data size
- Misaligned supervision risks catastrophic forgetting and the learning of spurious correlations rather than robust reasoning capabilities
Concrete Example:
When a small base model is forced to imitate a complex reasoning path from Llama-3.1-405B, it may fail to generalize because the reasoning style is 'perplexing' (high loss) to it. GRAPE would instead select a simpler, correct response that the base model assigns high probability to, facilitating effective learning.
Key Novelty
GRAPE (Generative Response Alignment for Pre-trained models)
- Instead of selecting the 'hardest' or 'highest quality' response, GRAPE selects the response that the base model itself finds most probable (lowest perplexity).
- It acts as a filter that tailors a diverse pool of candidate answers to the specific 'taste' (distribution) of the model being fine-tuned.
Architecture
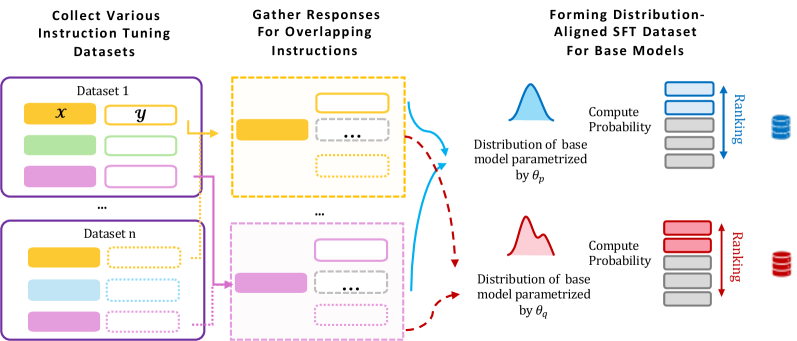
Conceptual flowchart of the GRAPE data selection process
Evaluation Highlights
- Outperforms the 'Strongest-Model Responses' baseline (using only Llama-3.1-405B data) by up to +13.8% absolute gain across reasoning benchmarks.
- Surpasses a baseline trained on 3x more data by up to +17.3%, proving that distributional alignment matters more than raw data scale.
- Allows Llama-3.1-8B to beat the Tulu-8B-SFT benchmark by +3.5% while using only 1/3 of the data and half the training epochs.
Breakthrough Assessment
8/10
Simple, compute-efficient method that challenges the 'stronger teacher is better' dogma in distillation. Demonstrates significant gains with less data/compute by prioritizing distributional fit.