📝 Paper Summary
LLM-as-a-Judge
Automated Evaluation
Reward Modeling
RISE-Judge is a generative judge model trained via a two-stage process (SFT warm-up and DPO enhancement) using highly efficient synthesized data, achieving state-of-the-art judgment accuracy while preserving general chat capabilities.
Core Problem
Training effective LLM judges typically requires massive, costly annotated datasets (600-900k entries), and many existing methods focus solely on judgment metrics, often degrading the model's general reasoning and chat abilities.
Why it matters:
- Manual annotation for RLHF is prohibitively expensive and slow for scaling modern LLMs, making accurate automated judges (LLM-as-a-Judge) critical
- Existing judge models often suffer from 'taxonomic forgetting' where they become good at scoring but lose general conversational ability
- Current data synthesis methods for judge training are inefficient, requiring hundreds of thousands of samples to achieve competitive performance
Concrete Example:
A standard judge model might correctly rate a math solution but fail to generate a coherent explanation or solve the math problem itself. RISE-Judge, conversely, can both accurately judge the error in a math problem (identifying specific logical flaws) and generate the correct step-by-step solution itself, as shown in the paper's case study on RewardBench math problems.
Key Novelty
Two-Stage 'Warm-up then Enhance' Training with Efficient Data Synthesis
- Decomposes training into 'SFT Warm-Up' (learning the format and reasoning style using CoT) and 'DPO Enhancement' (learning subtle preference distinctions on harder examples)
- Uses a data synthesis pipeline that rewrites instructions to be judge-specific, filters for position/length bias, and selects only 'hard' samples (where GPT-4o is inconsistent) for the DPO stage
- Demonstrates that training for judge capability—specifically the requirement to critically analyze and reason step-by-step—transfer positively to general reasoning tasks.
Architecture
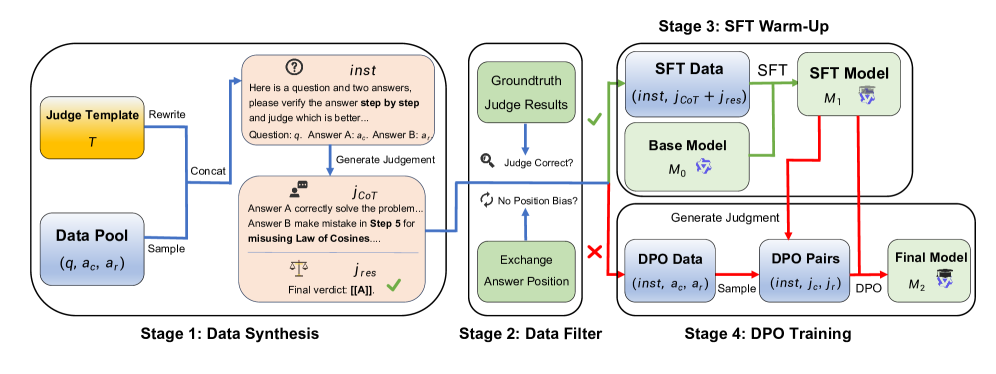
The data synthesis and two-stage training pipeline.
Evaluation Highlights
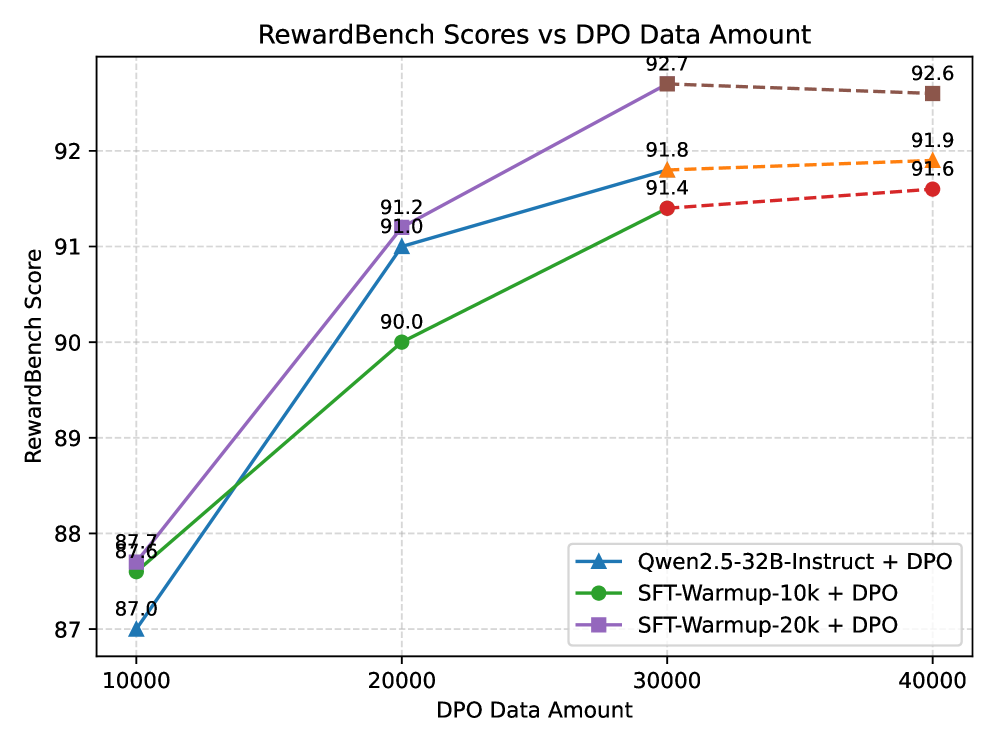
- Achieves SOTA on RewardBench (score 92.7) with only 40k training samples, outperforming GPT-4o and larger models that use 10-20x more data
- Matches the general chat performance of Qwen2.5-32B-Instruct on benchmarks like MMLU (82.7) and GSM8K (84.4), proving judge training doesn't degrade general ability
- Downstream policy models trained with RISE-Judge labels outperform those trained with GPT-4o labels on AlignBench (7.78 vs 7.61 overall score)
Breakthrough Assessment
8/10
Highly efficient data strategy (using <5% of typical data volume) to achieve SOTA is significant. Validating that judge training enhances general ability addresses a key concern in the field.