📝 Paper Summary
Vision-Language Models (VLMs)
Multimodal Reasoning
MiMo-VL-7B combines a four-stage pre-training pipeline enriched with synthetic Chain-of-Thought reasoning data and a post-training phase using Mixed On-policy Reinforcement Learning to achieve state-of-the-art multimodal performance.
Core Problem
Traditional VLM pre-training often relies on short QA pairs that lead to superficial pattern matching, while post-training rarely optimizes diverse capabilities (reasoning, grounding, preference) simultaneously.
Why it matters:
- Standard QA data restricts models to surface-level understanding, failing to develop complex logical reasoning required for 'thinking' models
- Simultaneously improving diverse capabilities (e.g., visual grounding vs. logical reasoning) is difficult due to interference and differing convergence rates across domains
Concrete Example:
In current VLMs, training on short-answer data prevents the model from learning generalizable reasoning patterns. Conversely, MiMo-VL incorporates synthesized long Chain-of-Thought data during pre-training to enable complex problem-solving in domains like STEM.
Key Novelty
Mixed On-policy Reinforcement Learning (MORL) & Reasoning-Heavy Pre-training
- Integrates diverse reward signals (perception accuracy, grounding precision, reasoning, human preference) into a single on-policy RL framework, unlike methods that optimize these separately.
- Injects massive amounts of synthetic reasoning data with long Chain-of-Thought directly into pre-training stages rather than just fine-tuning, preventing saturation and enabling deeper logic learning.
Architecture
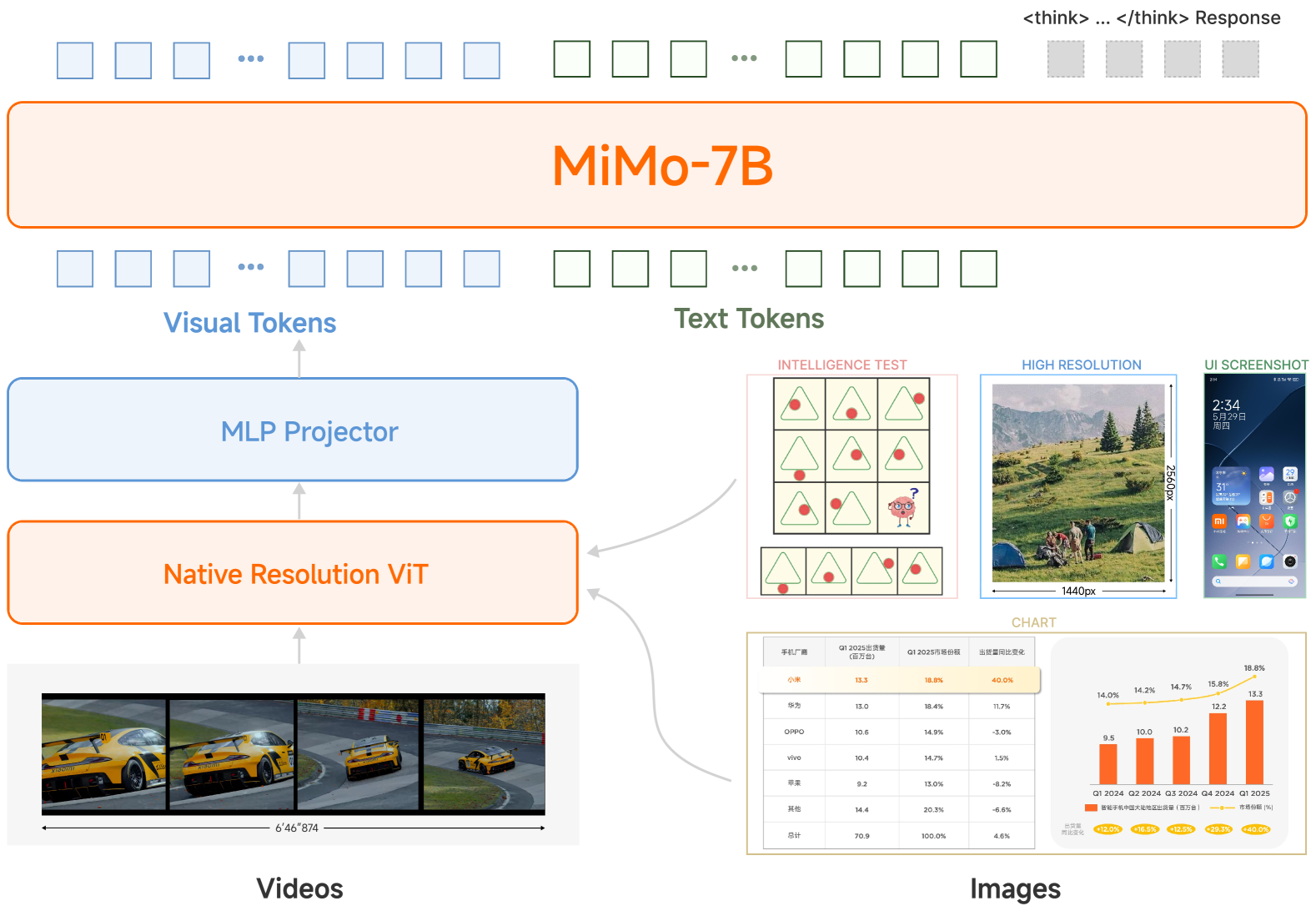
The overall architecture of MiMo-VL-7B, showing the Vision Transformer, MLP Projector, and LLM backbone.
Evaluation Highlights
- Outperforms Qwen2.5-VL-7B on 35 out of 40 evaluated tasks, achieving 66.7 on the MMMU benchmark.
- Sets a new state-of-the-art for GUI grounding with 56.1 on OSWorld-G, surpassing specialized models like UI-TARS.
- Achieves 59.4 on OlympiadBench, outperforming larger models with up to 78B parameters in multimodal reasoning.
Breakthrough Assessment
8/10
Strong performance for a 7B model, particularly in GUI agents and reasoning. The successful integration of mixed on-policy RL for multimodal tasks is a significant methodological consolidation.