📝 Paper Summary
LLM Reasoning
Reinforcement Learning (RL) Post-training
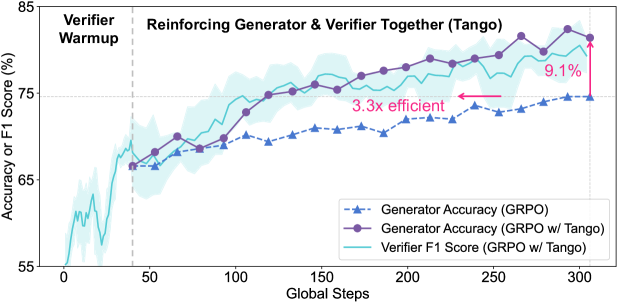
Tango improves LLM reasoning by jointly training a generator and a generative verifier via interleaved reinforcement learning, allowing the verifier to learn step-level critique strategies solely from outcome signals.
Core Problem
Current RL post-training methods rely on fixed or supervised-fine-tuned (SFT) verifiers, which cannot adapt to the generator's evolving capabilities and are vulnerable to reward hacking.
Why it matters:
- Fixed verifiers (rule-based or frozen) limit the generator's potential ceiling and fail to generalize to new reasoning paths
- SFT-trained verifiers are imitation-based, lacking the exploration needed to robustly distinguish correct reasoning from plausible-sounding errors
- When a generator improves, a static verifier becomes the bottleneck, unable to provide meaningful feedback on increasingly complex trajectories
Concrete Example:
A generator might produce a correct final answer using flawed logic (a false positive). A fixed verifier trained on static data might miss this subtle logical error. Tango's verifier, evolving alongside the generator, learns to penalize such 'lucky guesses' because it is optimized to align its step-judgments with true correctness over time.
Key Novelty
Generative Co-Evolutionary RL (Tango)
- Treats the Verifier as a policy trained via RL, not just a fixed regression model, allowing it to explore and refine its grading logic
- Interleaves training: the Generator improves using Verifier feedback, and the Verifier improves by learning to better predict the correctness of the Generator's new outputs
- Eliminates the need for expensive step-level human annotations; the Verifier learns 'what makes a step correct' purely from the final answer's correctness signal
Architecture
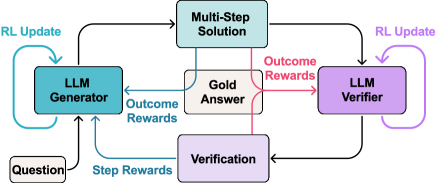
The overall Tango framework illustrating the interleaved training loop between the Generator and Verifier.
Evaluation Highlights
- Achieves an average relative improvement of 25.5% across five competition-level math benchmarks compared to vanilla RL (GRPO) baselines
- Doubles accuracy on the AIME 2025 benchmark relative to vanilla GRPO, demonstrating effectiveness on the hardest tasks
- Verifier establishes a new state-of-the-art on ProcessBench, outperforming the much larger Qwen2.5-Math-72B-Instruct despite being a 7B model trained without process labels
Breakthrough Assessment
9/10
Proposes a fundamental shift from fixed/SFT verifiers to RL-trained generative verifiers. The ability to learn process-level verification from outcome-only signals via co-evolution is a significant methodological advance.