📝 Paper Summary
Catastrophic Forgetting
Post-training adaptation
Alignment algorithms
Reinforcement learning minimizes catastrophic forgetting better than supervised fine-tuning because its use of on-policy data creates a mode-seeking objective that learns new tasks without disrupting the model's existing multi-modal prior knowledge.
Core Problem
Adapting language models to new tasks via Supervised Fine-Tuning (SFT) or Reinforcement Learning (RL) often degrades existing capabilities (e.g., safety, general knowledge), a phenomenon known as catastrophic forgetting.
Why it matters:
- Fine-tuning for instruction following or reasoning often unintentionally erodes safety guardrails (e.g., jailbreak resistance) or general world knowledge (e.g., MMLU performance)
- Understanding which alignment algorithm (SFT vs. RL) causes less forgetting is critical for building robust post-training pipelines
- Conventional wisdom regarding KL divergence (that mode-seeking behavior causes collapse) contradicts empirical findings that RL preserves knowledge better than SFT
Concrete Example:
When a Large Language Model (LLM) is fine-tuned on a math dataset, SFT may aggressively redistribute probability mass to cover the math answers, causing the model to 'forget' how to refuse unsafe prompts or answer general knowledge questions, whereas RL preserves these capabilities.
Key Novelty
Forgetting mitigation via on-policy data (Retaining by Doing)
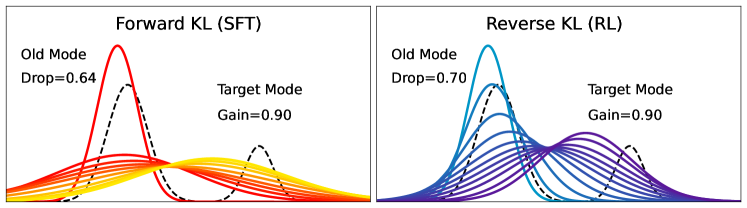
- Demonstrates that RL's robustness stems from its 'mode-seeking' nature (Reverse KL), which anchors the model to new task modes without stealing probability mass from old knowledge modes in a multi-modal distribution
- Identifies 'on-policy data' (sampling from the current model) as the practical driver of this robustness, rather than KL regularization or advantage estimation
- Proposes that SFT can achieve similar robustness if it uses 'approximately on-policy' data (generated at the start of each epoch) instead of fixed off-policy data
Architecture
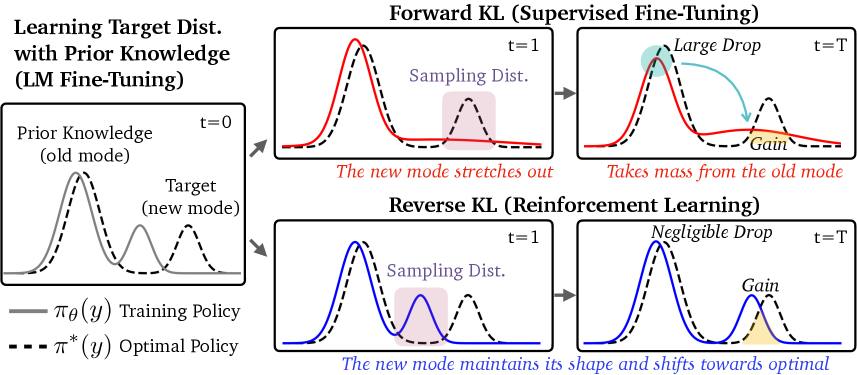
Illustration of Forward KL vs. Reverse KL dynamics on a multi-modal distribution.
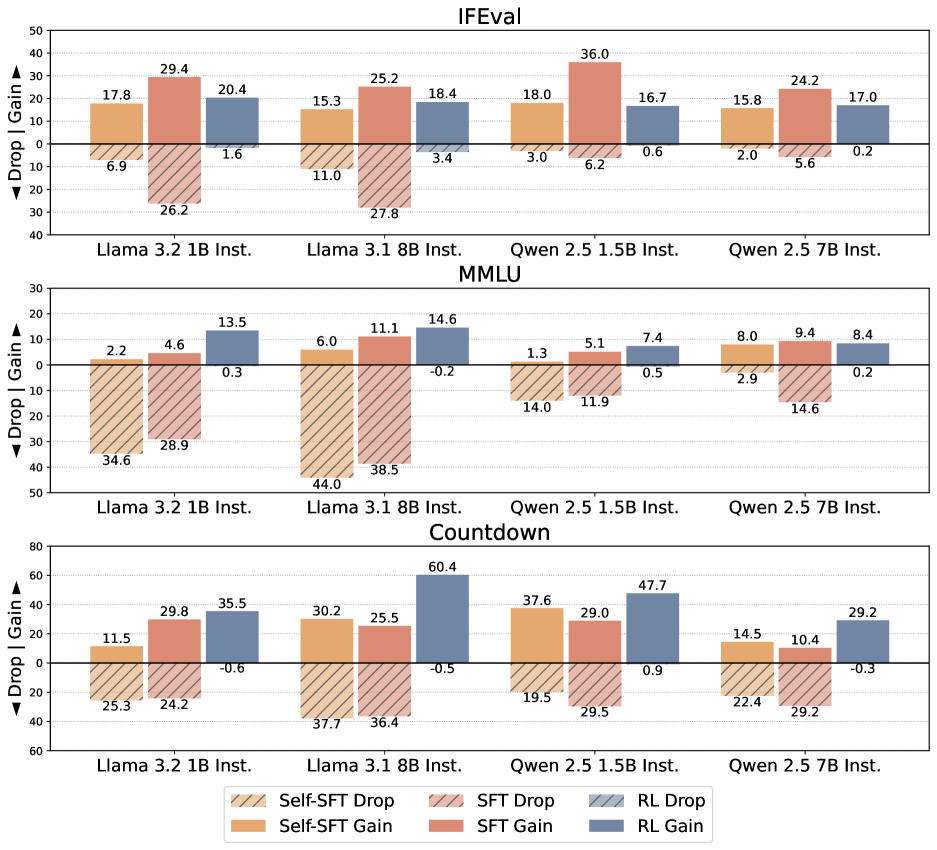
Evaluation Highlights
- In multi-modal Gaussian simulations, SFT (Forward KL) causes severe forgetting (0.12 drop in overlap area with prior knowledge) to reach 0.9 target gain, while RL (Reverse KL) keeps prior modes intact
- RL consistently achieves high target task performance with negligible drops on non-target tasks across Llama-3 and Qwen-2.5 families, whereas SFT shows a steep tradeoff
- Using approximately on-policy data in SFT significantly reduces forgetting compared to standard SFT, validating the theoretical insight
Breakthrough Assessment
8/10
Provides a counter-intuitive but theoretically grounded explanation for why RL preserves knowledge better than SFT, challenging conventional wisdom about KL divergence and offering a simple, actionable guideline (use on-policy data).