📝 Paper Summary
Multimodal Large Language Models (MLLMs)
Reinforcement Learning (RL) for Reasoning
A two-stage training framework for multimodal models that first establishes strong reasoning patterns via supervised fine-tuning (cold start) before refining them with reinforcement learning, outperforming RL-only approaches.
Core Problem
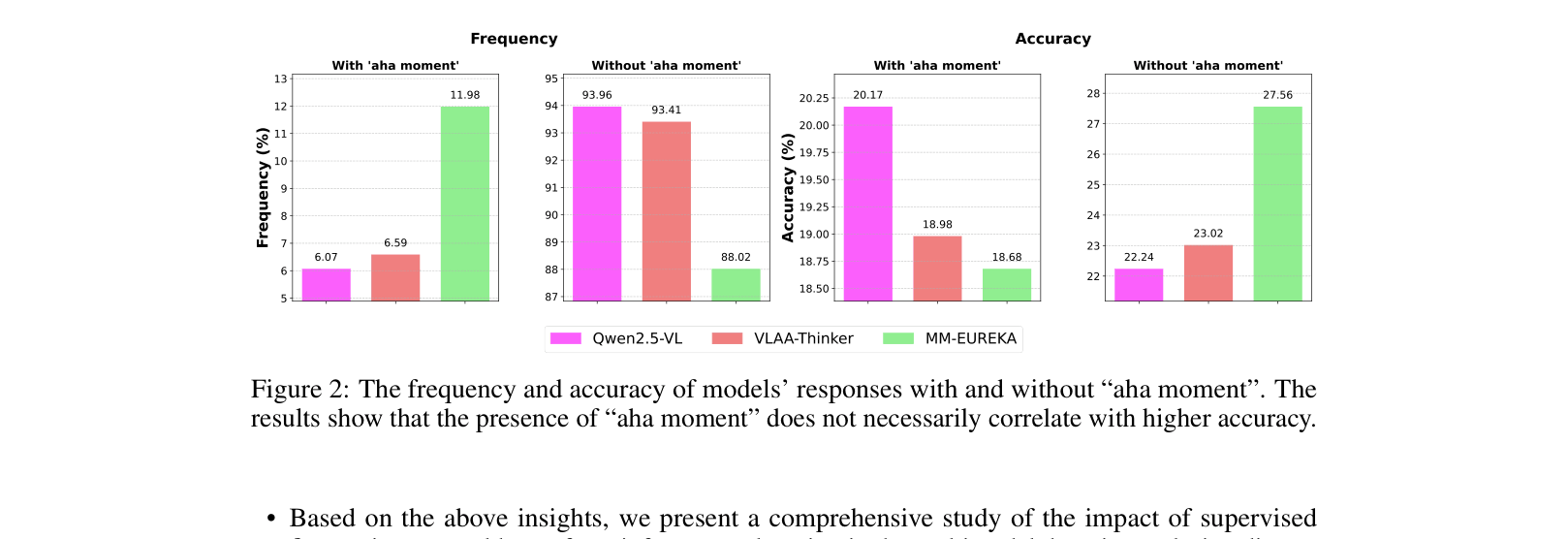
Directly applying reinforcement learning (Zero RL) to multimodal models often fails to induce genuine reasoning capabilities, as the observed 'aha moments' are frequently hallucinations rather than effective self-correction.
Why it matters:
- Current beliefs that 'aha moments' (reflective patterns) autonomously emerge and indicate improved reasoning in MLLMs may be misconceptions
- Reinforcement learning alone struggles to discover effective reasoning strategies from scratch in the multimodal domain without a strong initial foundation
- Existing methods either rely solely on SFT (Supervised Fine-Tuning) or jump straight to RL, missing the synergy of combining both for scalable reasoning
Concrete Example:
When solving a parallelogram geometry problem, a base model might generate reflective text like 'Wait, let's re-evaluate,' but then immediately proceed to use the same incorrect logic (e.g., claiming angles sum to 100° instead of 180°), showing that the pattern exists but is functionally useless.
Key Novelty
SFT-Cold-Start followed by GRPO (Group Relative Policy Optimization)
- Demonstrates that 'aha moment' patterns exist in base models prior to RL and do not inherently correlate with correctness, challenging the 'emergent' view
- Proposes explicitly initializing the model with high-quality Chain-of-Thought data (Cold Start) distilled from larger models before applying RL
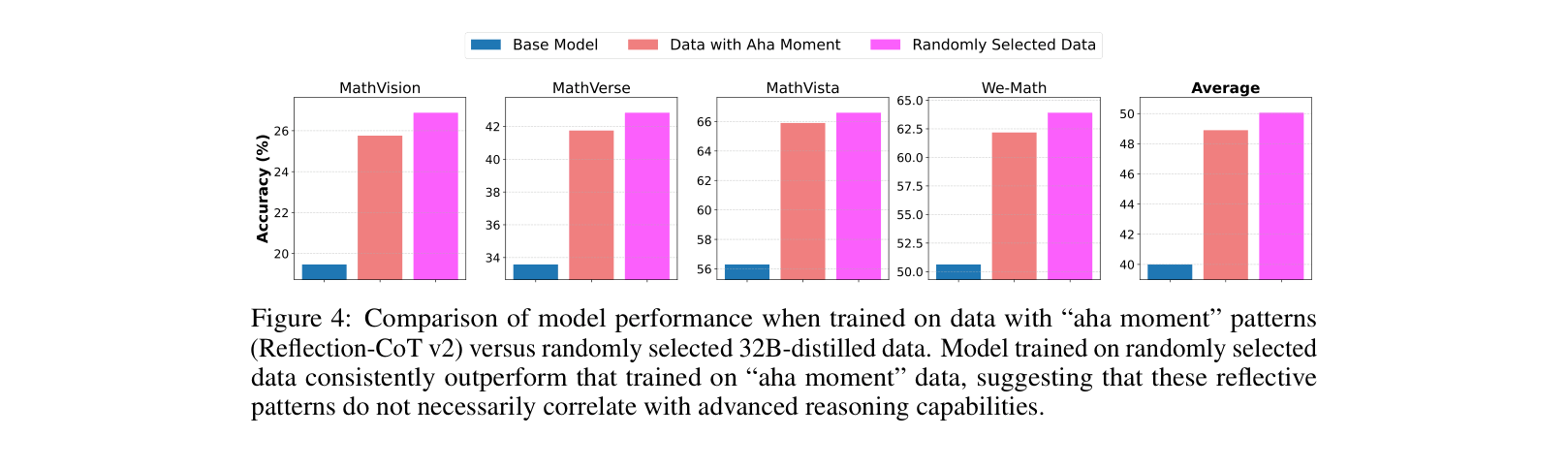
- Shows that reasoning *format* (structure) learned during cold start is crucial for subsequent RL success, even if the cold start data contains errors
Architecture
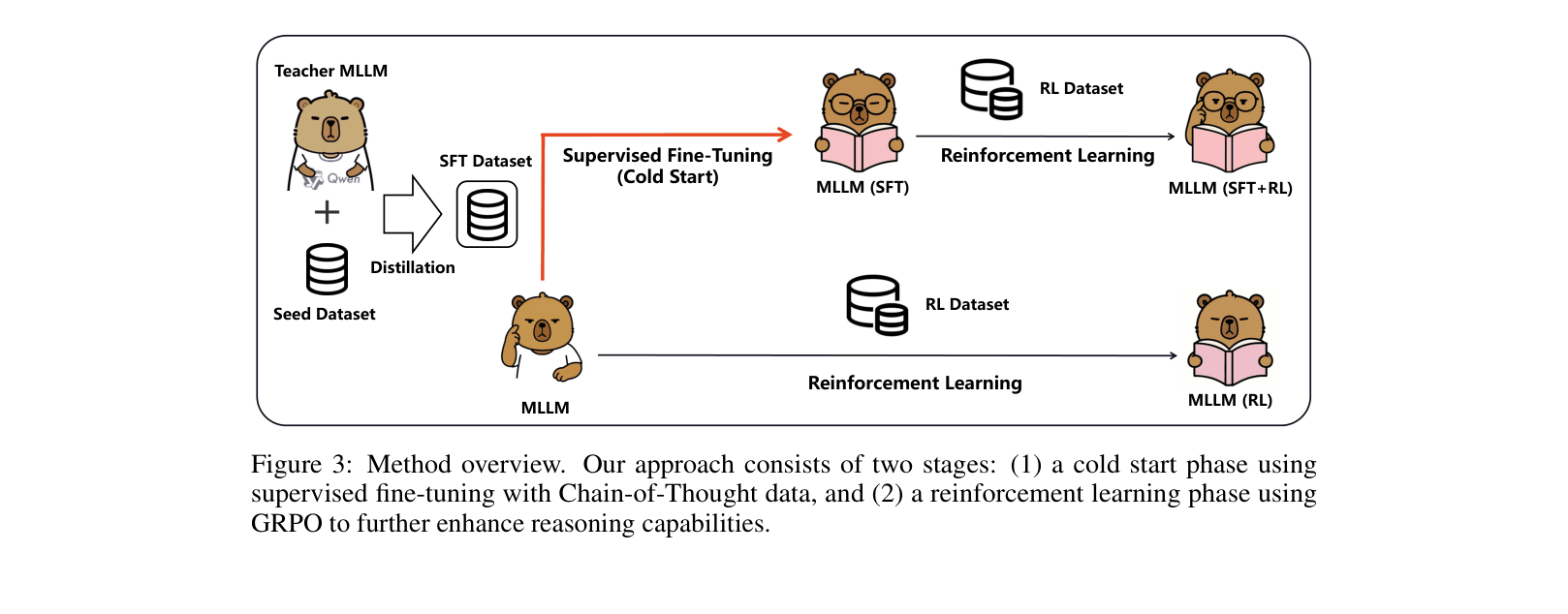
Overview of the two-stage training methodology: Cold Start (SFT) followed by Reinforcement Learning.
Evaluation Highlights
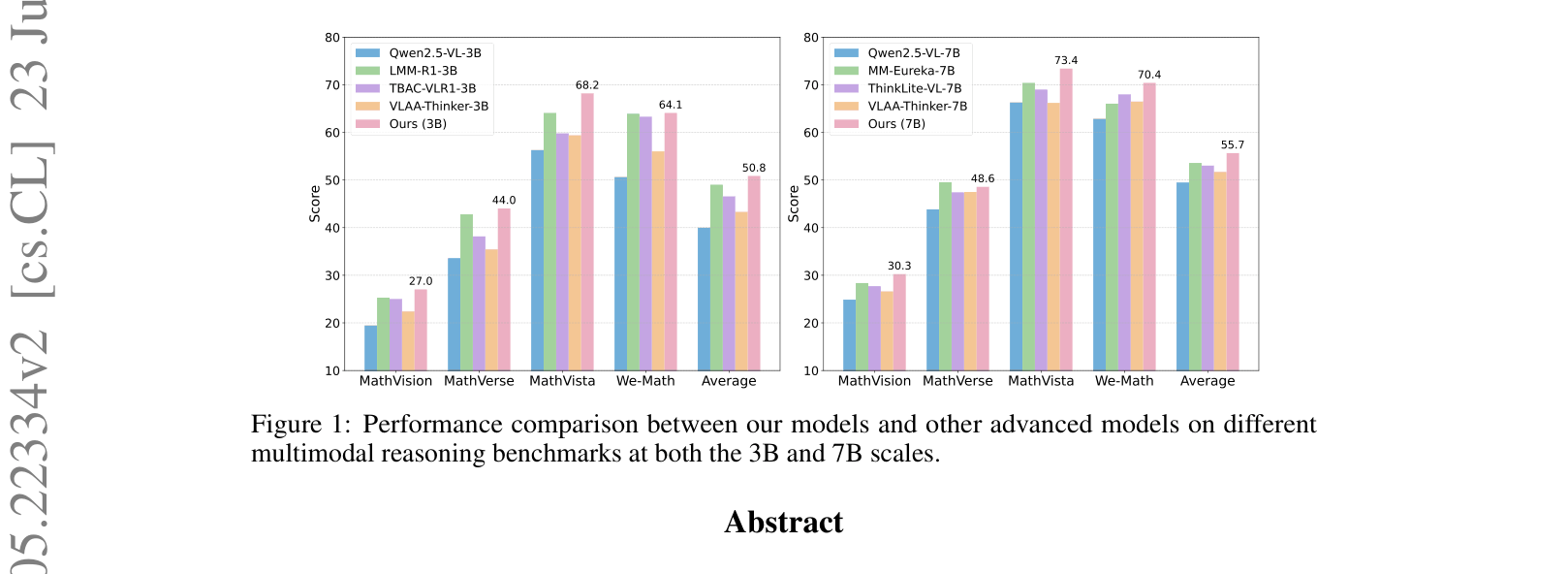
- +6.19 average score improvement on 4 multimodal benchmarks for the 7B model compared to the Qwen2.5-VL-7B base model
- +10.84 average score improvement for the 3B model, allowing it to outperform several 7B baselines like Qwen2.5-VL-7B and VLAA-Thinker-7B
- Achieves 73.4% on MathVista (7B model), surpassing GPT-4o (59.5%) and Skywork R1V (67.5%)
Breakthrough Assessment
8/10
Provides critical empirical evidence debunking the 'emergent aha moment' in current MLLM RL work and establishes a SOTA pipeline (SFT+RL) that allows 3B models to beat 7B baselines.