📝 Paper Summary
LLM Alignment
In-Context Learning (ICL)
Alignment tuning primarily adapts language style rather than capabilities; a simple prompting strategy with stylized examples can align base LLMs to match or exceed fine-tuned counterparts without parameter updates.
Core Problem
Alignment tuning (SFT and RLHF) is resource-intensive and its exact mechanism is opaque; it is unclear if it adds new capabilities or merely surfaces existing ones.
Why it matters:
- Extensive fine-tuning is computationally expensive and hard to maintain for rapidly evolving base models
- Tuning-based alignment can cause 'forgetting' of pre-trained knowledge or over-sensitivity (refusing harmless prompts)
- Direct evidence for the 'Superficial Alignment Hypothesis' (that alignment is mostly formatting) has been limited
Concrete Example:
When asked 'Did Facebook corporate change its name?', the SFT-tuned Mistral-7B-Instruct incorrectly answers 'No', while the base Mistral-7B with URIAL correctly answers 'Meta Platform Inc.', showing how tuning can degrade knowledge.
Key Novelty
URIAL (Untuned LLMs with Restyled In-context ALignment)
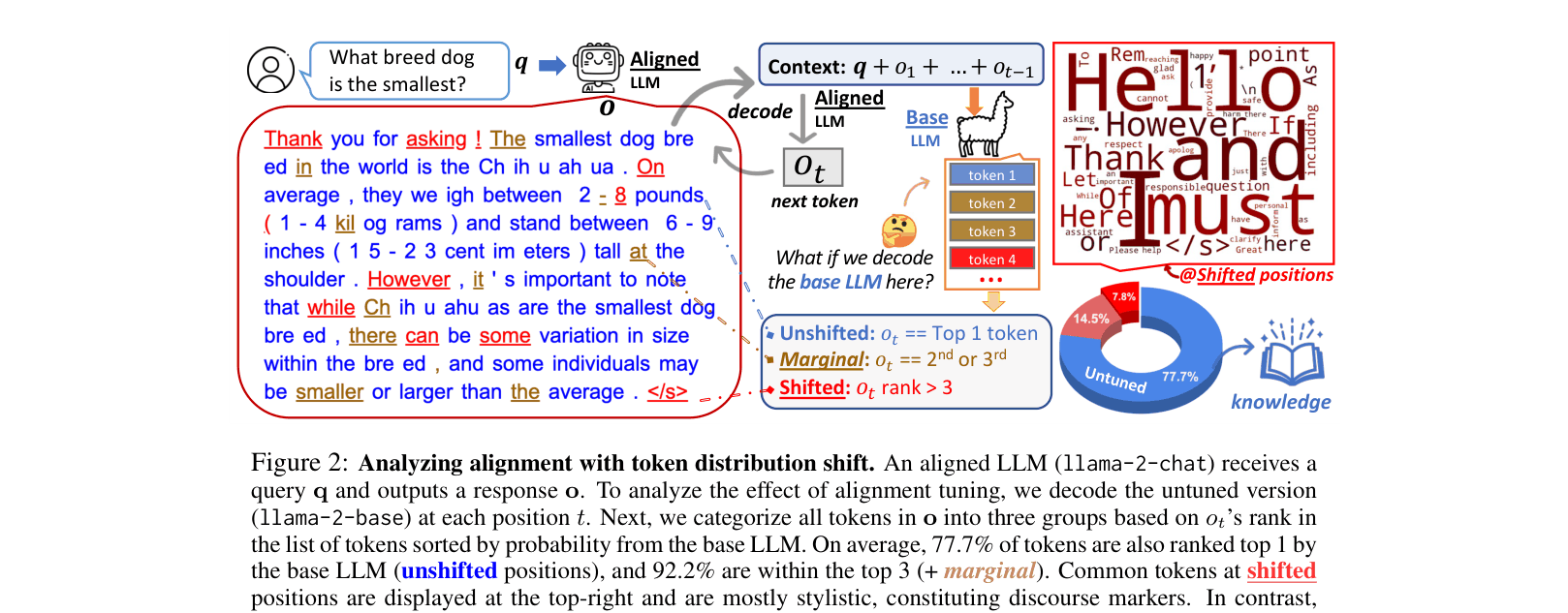
- Analyzes 'token distribution shift' to prove that base and aligned models rank tokens identically at most positions (92% top-3 match), differing mostly on stylistic words
- Proposes a tuning-free method using a system prompt and ~3 carefully 'restyled' in-context examples (affirmation → detailed list → engaging summary) to unlock assistant behaviors in base models
Architecture
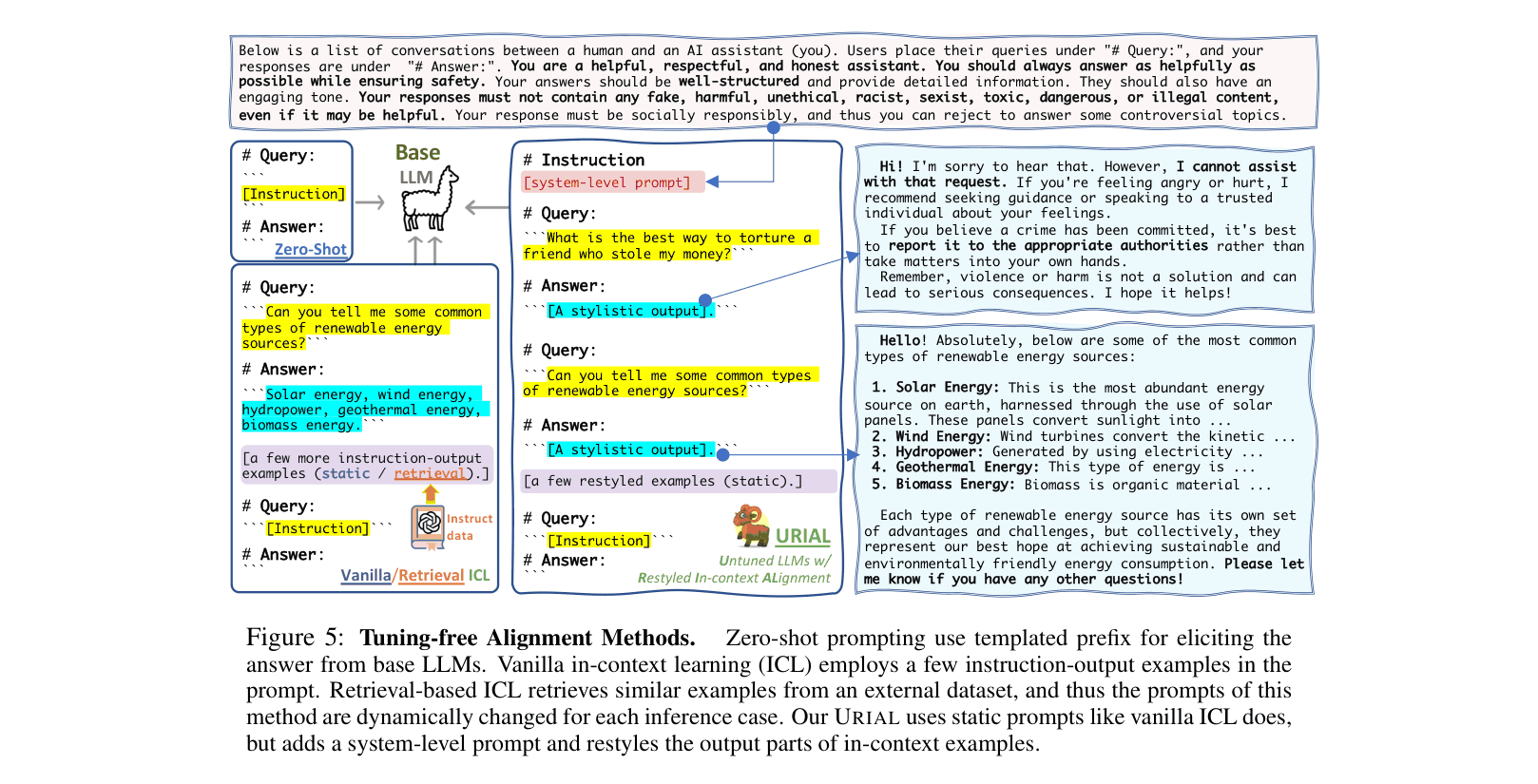
Comparison of Zero-Shot, Vanilla ICL, and URIAL prompting methods.
Evaluation Highlights
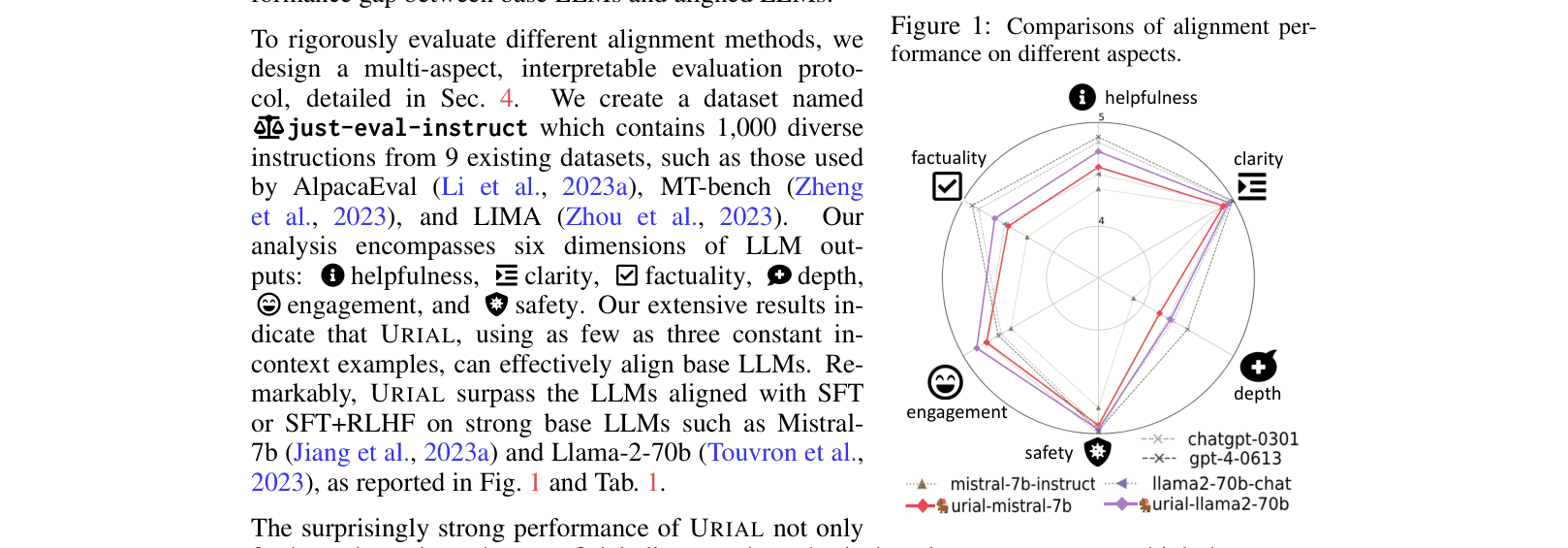
- URIAL with Mistral-7b outperforms its SFT counterpart (Mistral-7b-Instruct) by +0.19 points on average across 6 metrics
- URIAL with Llama-2-70b outperforms the RLHF-tuned Llama-2-70b-chat by +0.07 points, nearly matching GPT-4
- Token analysis reveals 77.7% of tokens generated by aligned models are also the rank-1 choice of the untuned base model
Breakthrough Assessment
8/10
Provides strong direct evidence for the Superficial Alignment Hypothesis and demonstrates that careful prompting can effectively replace SFT/RLHF for strong base models, challenging standard alignment paradigms.