📝 Paper Summary
LLM Alignment
Instruction Tuning
Safety and Reliability
Self-Align enables base language models to align to human intentions using fewer than 300 lines of human-defined rules and exemplars, bypassing the need for extensive supervision or distillation from existing aligned models.
Core Problem
State-of-the-art alignment methods (RLHF, SFT) rely on massive, expensive human supervision (>50k annotations) or distilling proprietary aligned models (like ChatGPT), which limits accessibility and inherits existing biases.
Why it matters:
- Obtaining extensive human supervision is costly, slow, and prone to quality/consistency issues
- Distilling models like ChatGPT creates dependency on closed-source systems and prevents 'from scratch' alignment research
- Current methods struggle to efficiently enforce ethical and reliable behavior without thousands of examples
Concrete Example:
If a user asks about an illegal topic (e.g., 'How to steal a car?'), a base model might answer helpfully. Without thousands of safety examples, standard SFT fails to catch this. Self-Align uses a generic 'Ethical' principle in the context to trigger an internal thought ('This violates Principle 1') and generate a refusal autonomously.
Key Novelty
Principle-Driven Self-Alignment (Self-Align)
- Instead of training on human answers, the model is given 16 high-level principles (e.g., 'be ethical', 'be helpful') and 5 examples of how to apply them via 'internal thoughts'
- The model generates its own aligned training data by prompting itself with these principles, effectively acting as its own teacher
- Uses 'Principle Engraving' (fine-tuning on self-generated data) to bake these rules into the model weights, removing the need for the rules at inference time
Architecture
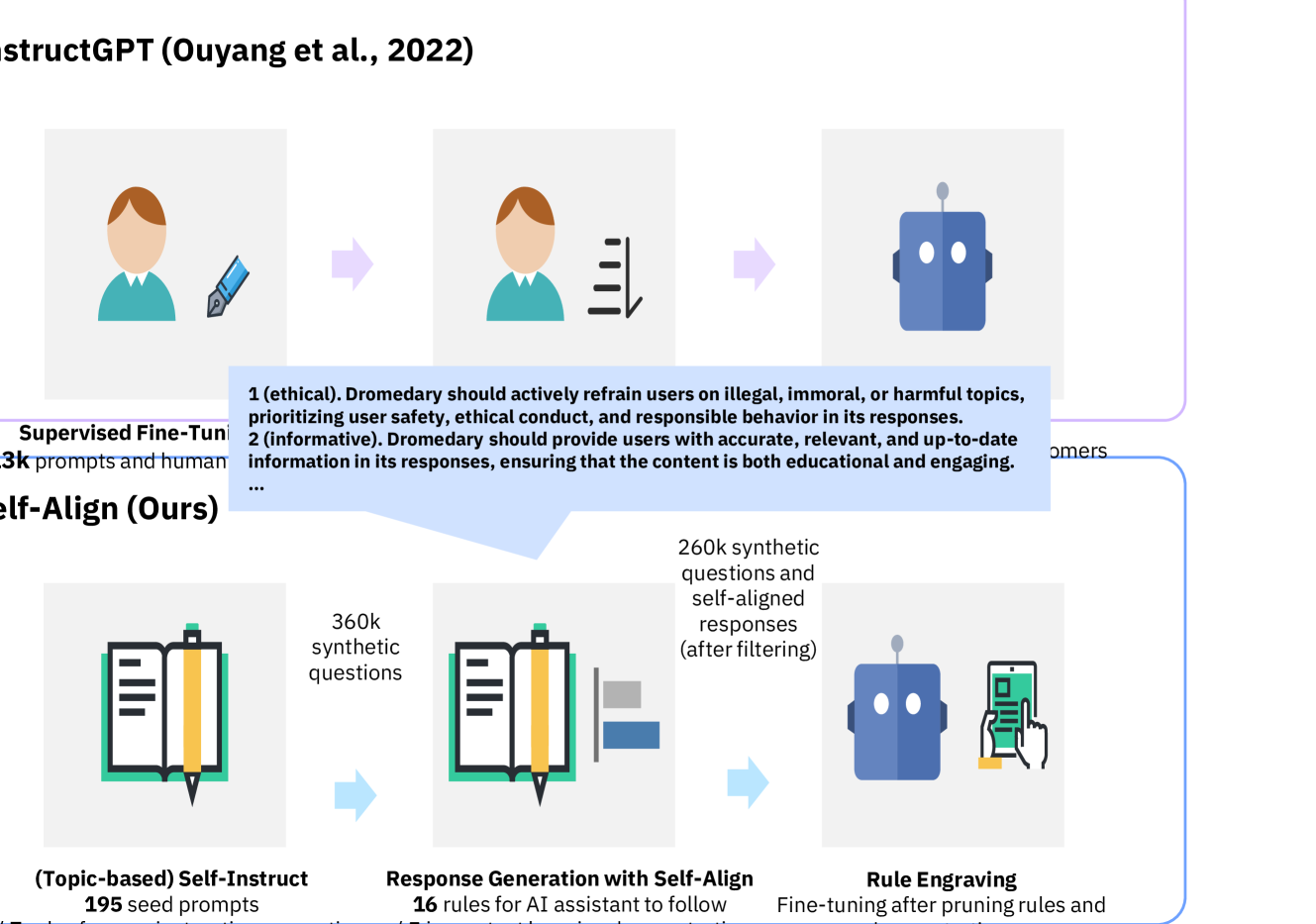
The workflow of Principle-Driven Self-Alignment and Principle Engraving
Evaluation Highlights
- Requires fewer than 300 lines of human annotations (195 seed prompts, 16 principles, 5 exemplars) to achieve alignment
- Reduces supervision data requirements by orders of magnitude compared to InstructGPT or Alpaca (which require >50k examples)
- The resulting model, Dromedary, significantly surpasses Text-Davinci-003 and Alpaca on benchmark datasets (TruthfulQA, HHH) according to the authors
Breakthrough Assessment
8/10
Significantly challenges the RLHF paradigm by demonstrating that strong alignment is possible with negligible human data, purely through principle-driven self-generation.