📝 Paper Summary
Mathematical Reasoning
Data Synthesis for LLMs
Supervised Fine-Tuning (SFT)
Standard small language models already possess latent math abilities that are masked by generation instability, which can be unlocked by scaling supervised fine-tuning with large amounts of synthetic data.
Core Problem
Small language models (e.g., LLaMA-2 7B) are widely believed to lack strong math capabilities without extensive pre-training, often showing low accuracy on benchmarks like MATH.
Why it matters:
- Current beliefs suggest only massive models (>50B parameters) or math-specific pre-training can achieve high performance, limiting accessibility and efficiency.
- The 'instability issue' means models often generate correct answers in latent space (high Pass@N) but fail to output them consistently (low Pass@1), wasting potential.
- Scaling supervised fine-tuning is typically limited by the scarcity of high-quality, publicly available math datasets.
Concrete Example:
On the MATH benchmark, a LLaMA-2 7B model achieves only 7.9% accuracy with a single generation (Pass@1), but 72.0% if allowed 256 attempts (Pass@256), proving it 'knows' the math but cannot reliably produce it.
Key Novelty
Xwin-Math (Scaling Synthetic SFT)
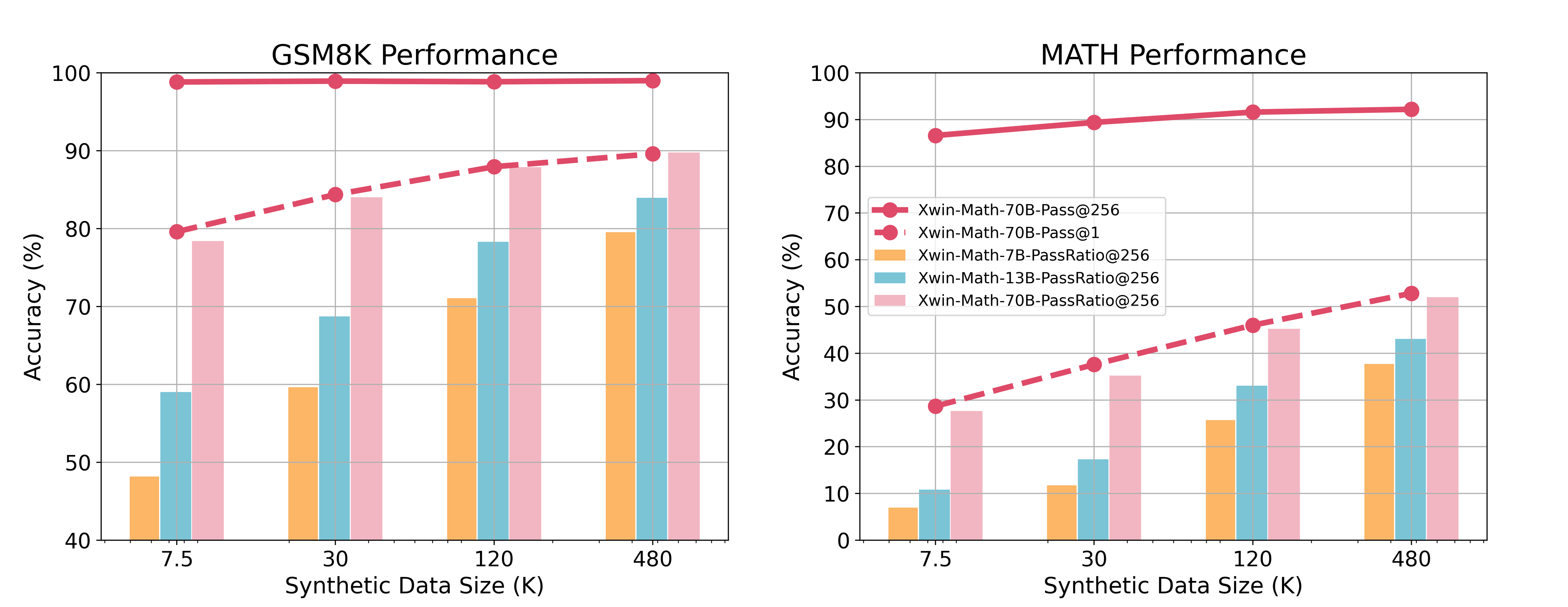
- Demonstrates that base LLaMA-2 models have high 'Pass@256' accuracy, indicating latent capability, but suffer from instability (low Pass@1).
- Uses GPT-4 Turbo to generate a massive scale of synthetic math questions (up to 960K) derived from existing datasets like GSM8K and MATH.
- Applies a 'verify-then-generate' pipeline where synthetic questions are validated by the generator itself before being used for large-scale SFT.
Architecture
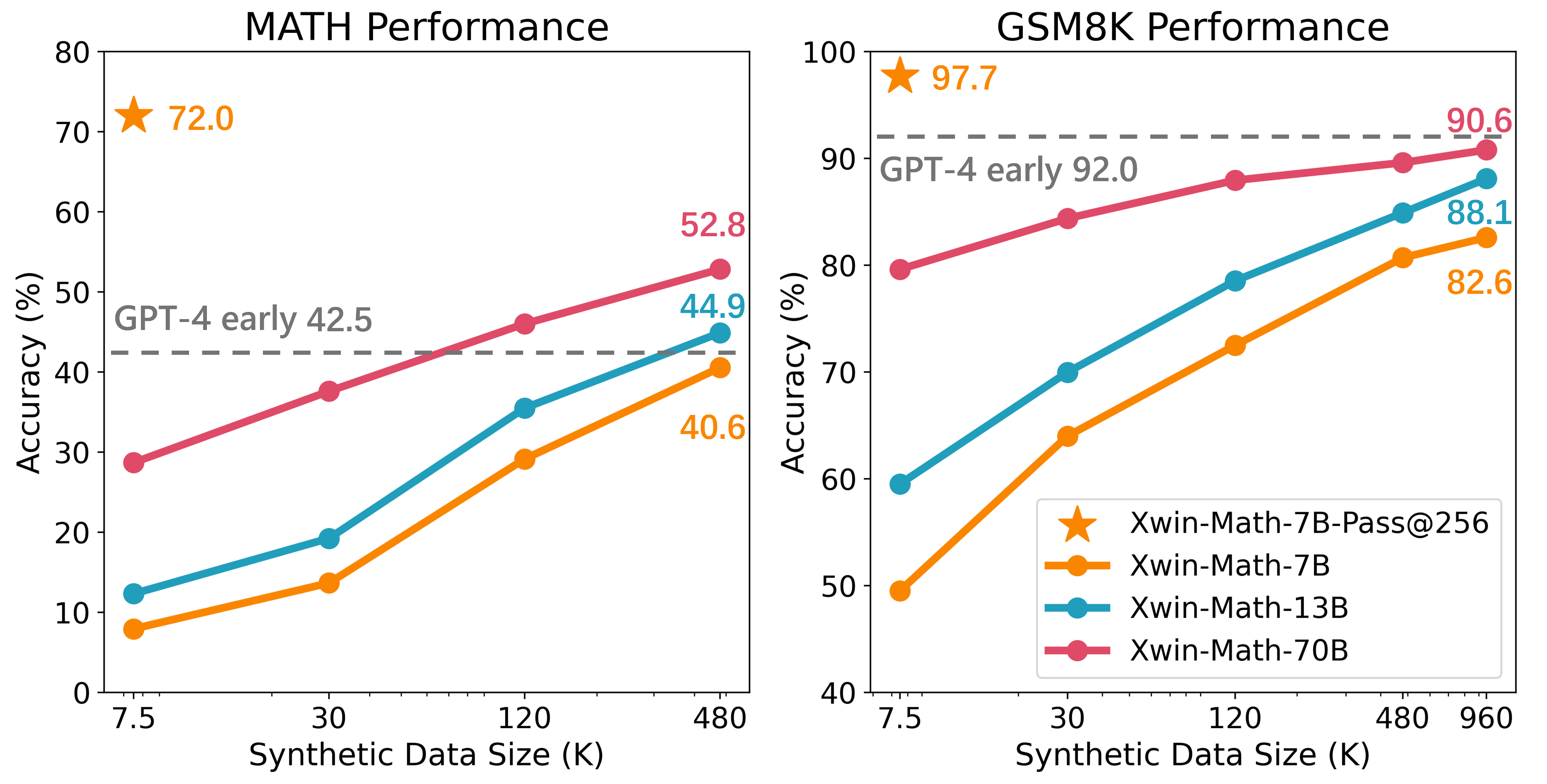
Scaling curves of accuracy on GSM8K and MATH benchmarks as a function of SFT data size, comparing real vs. synthetic data.
Evaluation Highlights
- LLaMA-2 7B achieves 82.6% on GSM8K using 960K synthetic samples, outperforming previous 7B baselines by +14.2%.
- LLaMA-2 7B reaches 40.6% on the difficult MATH benchmark, surpassing previous state-of-the-art 7B models by +20.8%.
- LLaMA-2 70B achieves 90.6% on GSM8K and 52.8% on MATH, outperforming GPT-4-0314 on the MATH benchmark.
Breakthrough Assessment
8/10
Significantly shifts the perspective on small model capabilities, showing that data scaling in SFT—not just pre-training—can unlock strong reasoning. Achieves SOTA for open-source models at the time.