📝 Paper Summary
GUI Agents
Visual Grounding
Reinforcement Learning
SE-GUI improves how agents locate interface elements by using distance-based feedback and filtering training data based on whether the model's own attention maps focus on the correct regions.
Core Problem
Existing GUI agents rely on Supervised Fine-Tuning (SFT) which generalizes poorly to complex screens, while standard Reinforcement Learning (RL) struggles because binary success/failure rewards are too sparse for precise coordinate prediction.
Why it matters:
- Sparse rewards (0/1) in early training mean incorrect predictions get identical zero feedback, preventing the model from learning 'near misses'
- Automated grounding datasets often contain noise (e.g., hidden DOM elements), causing models to learn incorrect associations between instructions and visual locations
- Current SFT methods require massive datasets yet fail to scale to high-resolution professional environments compared to human-like iterative learning
Concrete Example:
If a model clicks slightly to the left of a button, a standard binary reward gives it a '0' (same as clicking the opposite side of the screen). SE-GUI gives a partial reward based on proximity. Additionally, if the training data has a label for a hidden button, standard methods train on noise, whereas SE-GUI detects its attention is unfocused and ignores the bad sample.
Key Novelty
Self-Evolutionary Reinforcement Fine-Tuning (SE-RFT)
- Introduces a 'Dense Point Reward' that gives continuous feedback based on pixel distance to the target, rather than just success/failure, guiding the model toward precise coordinates
- Implements a self-supervision loop where the model's own attention maps are analyzed; if the model doesn't focus on the target region during training, that specific sample is dynamically filtered out to prevent noise
Architecture
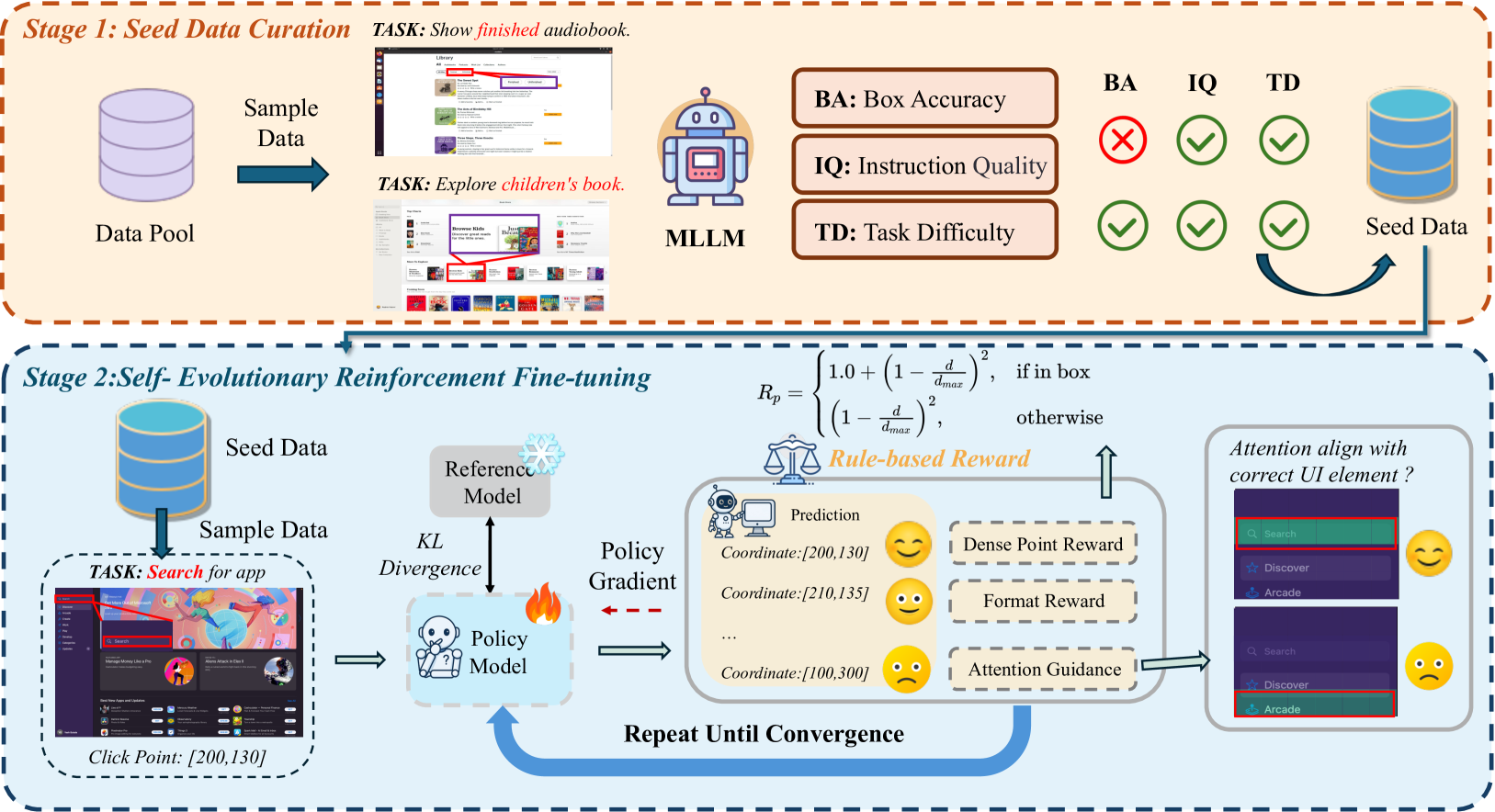
The overall SE-GUI framework including data curation, the RL training loop with dense rewards, and the attention-based filtering mechanism.
Evaluation Highlights
- Achieves 47.3% accuracy on ScreenSpot-Pro, a challenging high-resolution benchmark
- Outperforms the massive UI-TARS-72B model by a margin of 24.2% while using only a 7B parameter model
- Attains state-of-the-art results using only 3,018 high-quality training samples, demonstrating extreme data efficiency compared to SFT
Breakthrough Assessment
8/10
Significant efficiency jump: beats a 72B model with a 7B model using only 3k samples. The attention-guided data filtering is a clever, methodologically sound way to handle noisy GUI data.