📊 Experiments & Results
Evaluation Setup
Math word problem solving on standard benchmarks
Benchmarks:
- GSM8K (Grade school math word problems)
- SVAMP (Math word problems with varying difficulty)
Metrics:
- maj@1 (Greedy Accuracy)
- maj@96 (Majority vote at 96 samples)
- rerank@96 (Best of 96 selected by ORM)
- pass@96 (Oracle best of 96)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Comparison of different RL algorithms on GSM8K using Llama-2-13B initialized from an SFT checkpoint. | ||||
| GSM8K | maj@1 | 0.459 | 0.530 | +0.071 |
| GSM8K | maj@96 | 0.640 | 0.729 | +0.089 |
| GSM8K | pass@96 | 0.840 | 0.860 | +0.020 |
| Performance on SVAMP without SFT initialization (Pretrained 2-shot). | ||||
| SVAMP | maj@1 | 0.05 | 0.69 | +0.64 |
Experiment Figures
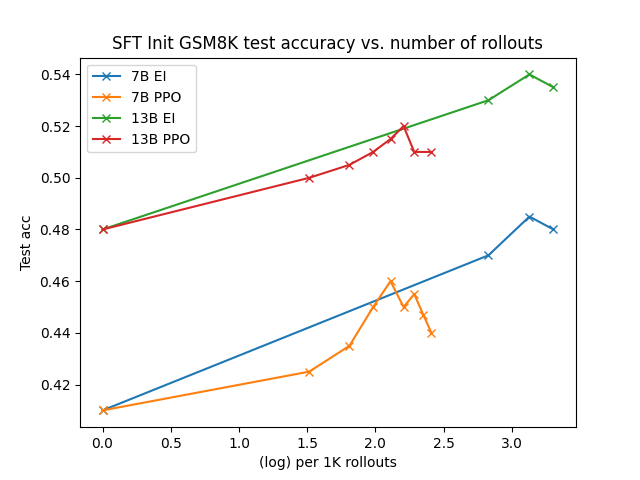
Maj@1 accuracy on GSM8K vs. training iterations for Expert Iteration
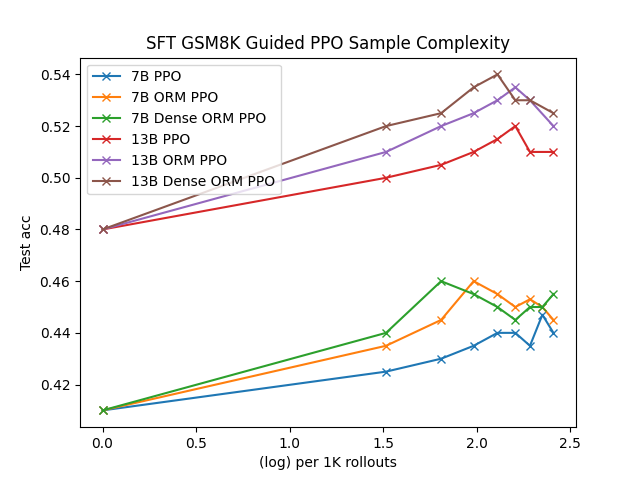
Maj@1 accuracy vs. number of model rollouts (samples) for PPO and EI
Main Takeaways
- Expert Iteration consistently performs best across metrics and initializations, often beating PPO.
- Sample complexity of Expert Iteration is surprisingly similar to PPO when normalized for samples per prompt.
- RL fine-tuning improves both greedy accuracy (maj@1) and diversity (pass@96) simultaneously, whereas continued SFT degrades diversity.
- Models fail to explore significantly beyond the solutions produced by SFT; pass@96 saturates early in RL training.
- Dense rewards (intermediate supervision) do not provide significant benefits over sparse outcome-based rewards for these tasks.