📝 Paper Summary
Text-to-Image Generation
Multimodal Large Language Models (MLLMs)
Autoregressive Modeling
Lumina-mGPT demonstrates that a simple decoder-only autoregressive model can achieve photorealistic image generation comparable to diffusion models by initializing from a pretrained multimodal backbone and using a progressive resolution-flexible finetuning strategy.
Core Problem
Existing autoregressive vision models struggle with high-quality photorealistic generation, lack flexibility in resolution/aspect ratio, and rely on complex non-scalable architectures compared to diffusion models.
Why it matters:
- Autoregressive models excel at reasoning and text generation but lag behind diffusion models in image quality, creating a gap in unified modeling.
- Current AR image models often produce small, fixed-resolution images (e.g., 256x256), limiting their practical utility.
- Encoder-decoder architectures used in prior works (Parti, Unified-IO) are less scalable and harder to unify with standard LLM infrastructures than decoder-only designs.
Concrete Example:
When a standard AR model generates a 'panoramic landscape', it might be forced into a square 256x256 crop, distorting the content. Furthermore, 1D token sequences for 512x512 and 256x1024 images are indistinguishable to the model without explicit structural markers, leading to ambiguous generation.
Key Novelty
Flexible Progressive Supervised Finetuning (FP-SFT) on top of Multimodal Generative Pretraining (mGPT)
- Initializes a decoder-only transformer from a strong multimodal base (Chameleon) rather than random initialization, accelerating convergence.
- Introduces Unambiguous Image Representation (Uni-Rep) by inserting height/width and end-of-line tokens into the sequence, allowing the model to distinguish and generate varying aspect ratios naturally.
- Employes a 'weak-to-strong' training curriculum, starting with low-resolution/high-throughput training and progressively moving to high-resolution fine-tuning.
Architecture
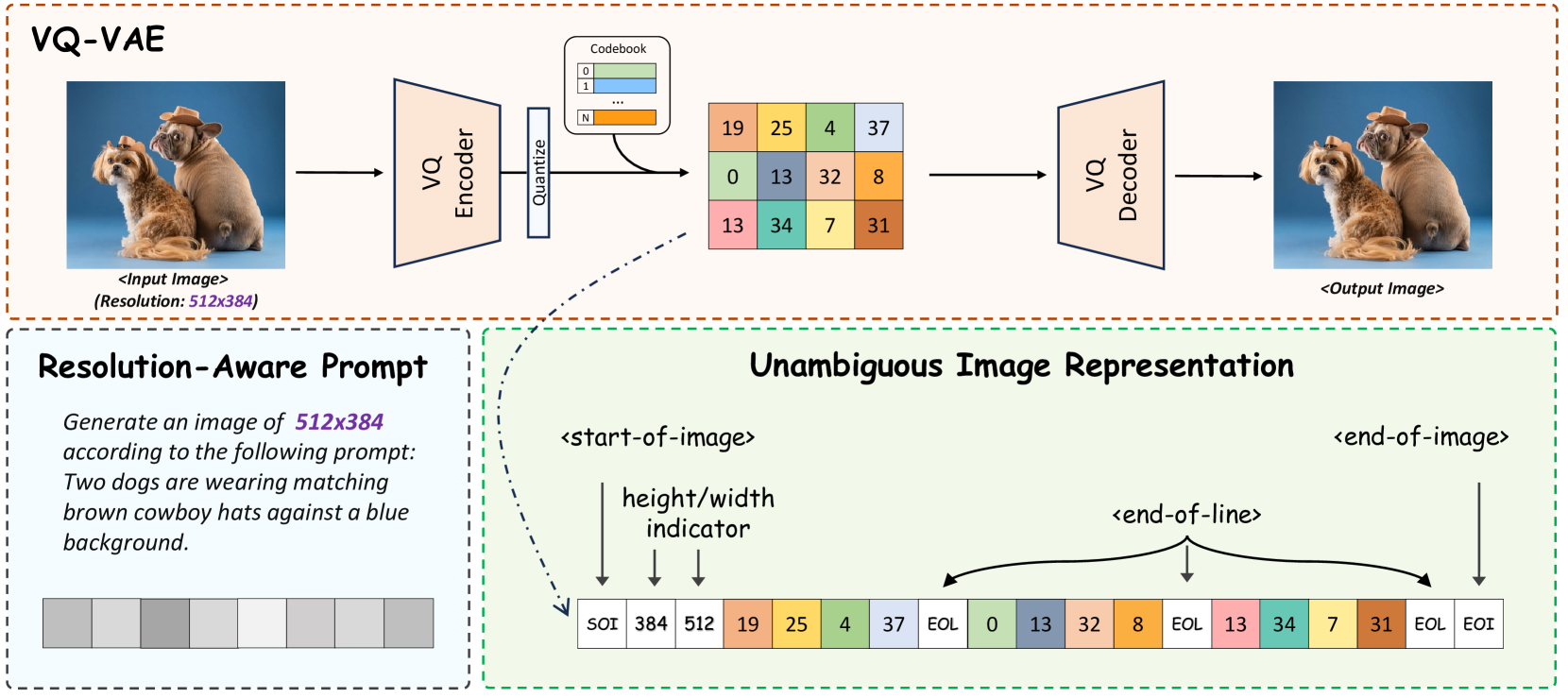
Overview of the Unambiguous Image Representation (Uni-Rep) and the resolution-aware prompting mechanism.
Evaluation Highlights
- Achieves image generation performance comparable to modern diffusion models (e.g., SD3, DALL-E 3) using a decoder-only AR architecture.
- Trains a 7B model in just 7 days on 32 A100 GPUs, demonstrating high efficiency due to mGPT initialization.
- Demonstrates 'omnipotent' capabilities, performing text-to-image, image editing, segmentation, depth estimation, and visual QA within a single unified model.
Breakthrough Assessment
8/10
Significantly closes the gap between AR and diffusion for image generation while maintaining the advantages of a unified decoder-only interface. The efficiency and flexibility claims are strong contributions to the open-source domain.
