📝 Paper Summary
Discrete Masked Diffusion Language Models (MDLM)
Block Diffusion Language Models (BDLM)
Large Language Model Pre-training
LLaDA2.0 scales diffusion language models to 100 billion parameters by converting pre-trained auto-regressive models via a three-phase Warmup-Stable-Decay strategy that balances knowledge inheritance with bidirectional diffusion capabilities.
Core Problem
Training large-scale diffusion language models from scratch is prohibitively expensive, but direct conversion from standard auto-regressive models fails due to the distribution gap between left-to-right generation and bidirectional denoising.
Why it matters:
- Auto-regressive models suffer from sequential inference bottlenecks, preventing parallel generation and increasing latency at scale
- Existing diffusion models are limited to small scales (≤8B) due to training costs, failing to match the performance of 100B+ frontier models
- Bridging the gap allows diffusion models to inherit the vast knowledge of existing pre-trained AR models while enabling fast parallel decoding
Concrete Example:
When directly training a diffusion model initialized from an AR model, the mismatch between the AR's causal attention and the diffusion model's bidirectional requirement leads to unstable optimization and catastrophic forgetting of linguistic knowledge. LLaDA2.0 avoids this by gradually transitioning block sizes.
Key Novelty
Warmup-Stable-Decay (WSD) Continual Pre-training
- Warmup: Gradually increases the block size in Block Diffusion from small spans to the full sequence, allowing the AR model to slowly adapt to bidirectional diffusion context
- Stable: Trains on full-sequence masked diffusion (MDLM) at large scale to solidify global denoising capabilities
- Decay: Reverts to a compact block size to distill global knowledge back into a blockwise structure optimized for efficient KV-cache reuse during inference
Architecture
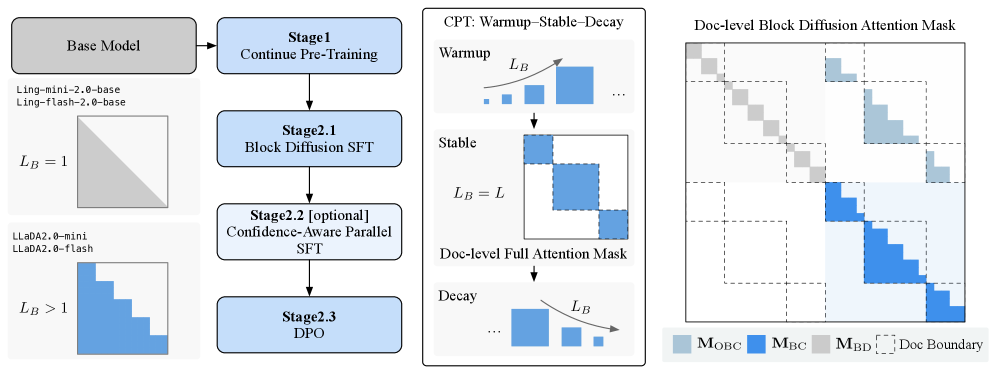
The holistic training pipeline of LLaDA2.0, showing the transition from AR to Diffusion.
Evaluation Highlights
- LLaDA2.0-flash (100B) enables parallel decoding, surpassing the inference speed of equivalently sized auto-regressive models
- Successfully scales diffusion language models to 100B parameters (LLaDA2.0-flash) and 16B parameters (LLaDA2.0-mini) via continual pre-training
- Achieves competitive performance on standard benchmarks by inheriting knowledge from strong AR base models (Ling-mini-2.0 and Ling-flash-2.0)
Breakthrough Assessment
8/10
First successful scaling of diffusion language models to the 100B parameter frontier. The WSD strategy offers a practical recipe for converting existing AR models to diffusion, potentially shifting the paradigm for efficient large-scale inference.