📝 Paper Summary
Synthetic data generation
Instruction tuning for mathematics
OpenMathInstruct-2 is a massive open-source math instruction dataset created by optimizing data synthesis choices (solution format, teacher strength, question diversity) rather than aggressive filtering.
Core Problem
High-quality mathematical reasoning data is largely closed-source or restrictively licensed (e.g., GPT-generated), preventing researchers from understanding synthesis trade-offs and building strong open models.
Why it matters:
- Closed data prevents the community from understanding the impact of algorithmic choices like CoT formats or teacher models on performance
- Restrictive licenses on datasets like NuminaMath (generated by GPT-4o) prohibit commercial use
- Previous open datasets like OpenMathInstruct-1 lack question diversity and representation of challenging problems
Concrete Example:
Existing open datasets rely on fixed training sets (MATH/GSM8K), limiting diversity. A model trained on just 1K unique questions drops over 10% in accuracy compared to 6.5K questions, showing that simple solution augmentation isn't enough.
Key Novelty
Optimized Synthetic Data Pipeline for Math (OpenMathInstruct-2)
- Synthesize 14M question-solution pairs using a strong open-weight teacher (Llama-3.1-405B) rather than weak student self-generation
- Augment question diversity significantly by prompting the teacher to create new variations of seed problems, rather than just solving existing ones
- Replace standard verbose Chain-of-Thought with a concise 'OpenMath CoT' format that strips unnecessary verbiage
Architecture
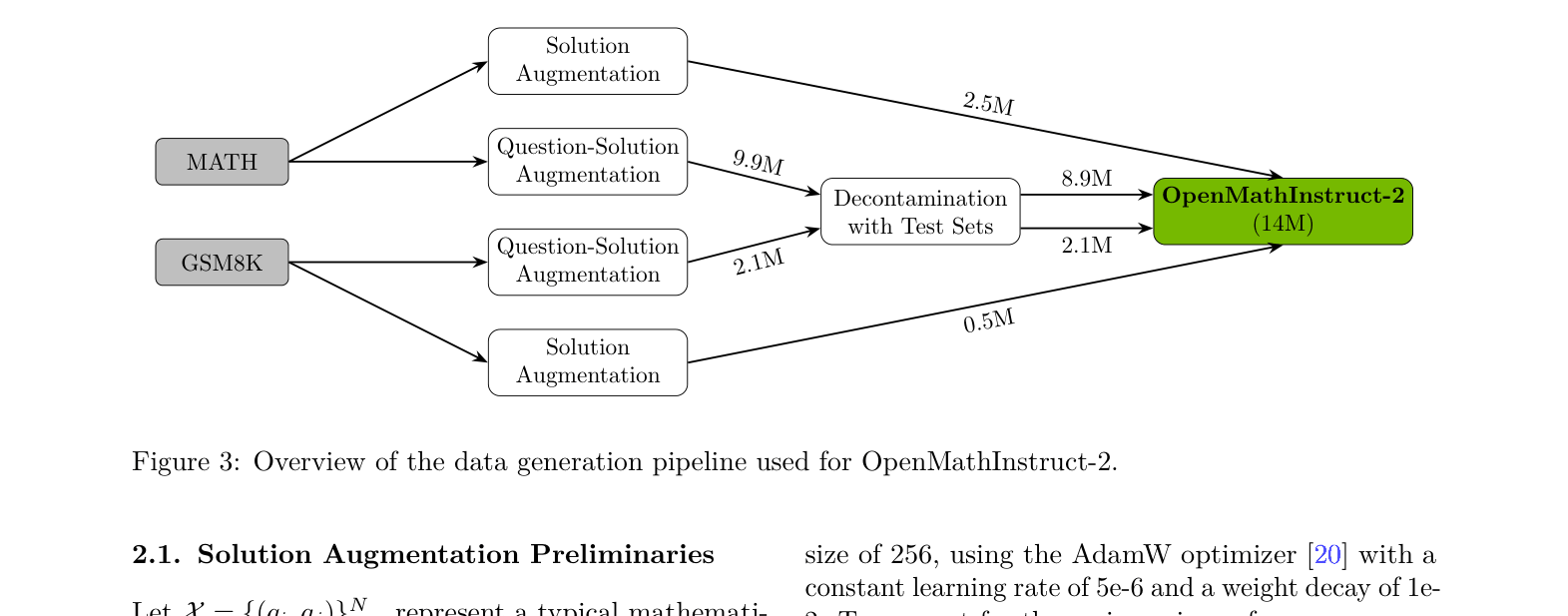
Overview of the data generation pipeline for OpenMathInstruct-2.
Evaluation Highlights
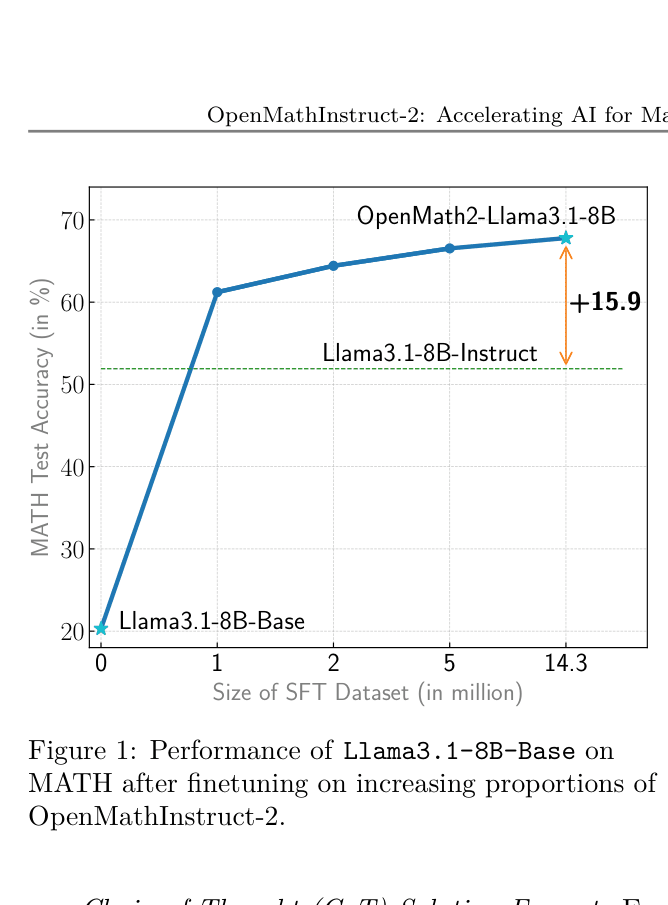
- +15.9% absolute improvement on MATH benchmark for Llama-3.1-8B-Base finetuned on OpenMathInstruct-2 compared to Llama3.1-8B-Instruct (51.9% → 67.8%)
- Outperforms NuminaMath-7B-CoT (previous best open-source) on GSM8K (91.7% vs 75.4%) and MATH (67.8% vs 55.2%)
- The finetuned Llama-3.1-70B model achieves 71.9% on MATH, surpassing the official Llama3.1-70B-Instruct (67.9%)
Breakthrough Assessment
9/10
Significantly advances open-source math reasoning by providing a commercially usable dataset 8x larger than prior open alternatives and establishing strong baselines that beat official instruct models.