📝 Paper Summary
Data Distillation
Code Generation
Reasoning Models
OpenCodeReasoning is a large-scale dataset of 736k reasoning-augmented coding solutions used to fine-tune standard LLMs, allowing them to outperform similarly sized models trained with reinforcement learning.
Core Problem
While reasoning models like DeepSeek-R1 excel at coding through reinforcement learning, the data and methods to distill these capabilities into smaller, more efficient models are often proprietary or small-scale.
Why it matters:
- High-quality human-labeled coding data is scarce and expensive, creating a bottleneck for improving non-reasoning models.
- Current open-weight reasoning models rely on complex RL training pipelines, while the potential of pure Supervised Fine-Tuning (SFT) with large-scale reasoning data remains under-explored.
- Existing reasoning datasets for code are small (17k-114k samples), limiting the performance gains achievable by distilled student models.
Concrete Example:
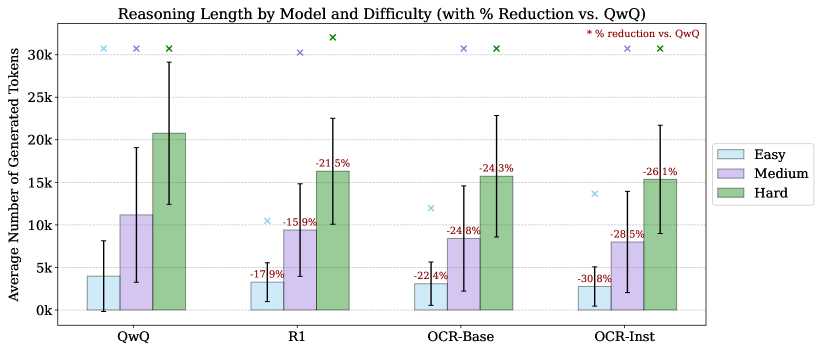
A standard instruction-tuned model often fails hard competitive programming problems because it jumps to code generation without planning. In contrast, R1 models generate long 'thinking' traces before coding, but smaller models haven't successfully mimicked this behavior at scale.
Key Novelty
OpenCodeReasoning (Large-Scale Reasoning Distillation)
- Constructs the largest reasoning-based coding dataset (736k samples) by filtering high-difficulty problems and generating solutions with DeepSeek-R1.
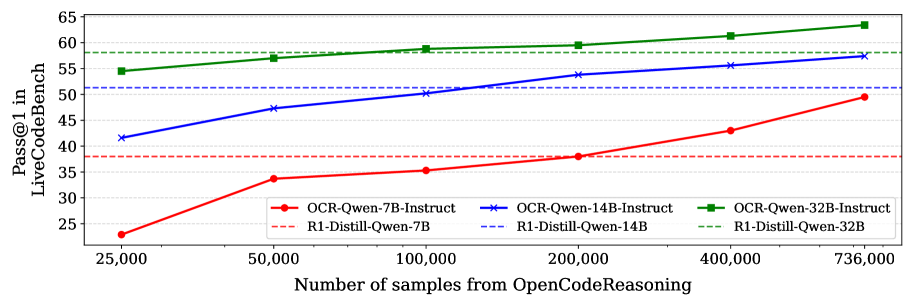
- Demonstrates that pure SFT on extensive reasoning traces allows standard models (Qwen2.5) to surpass specialized RL-trained models (R1-Distill-Qwen) without needing RL themselves.
- Validates a counter-intuitive filtering strategy: prioritizing instruction diversity and problem hardness over perfect solution correctness (finding that models learn well even from incorrect solutions).
Architecture
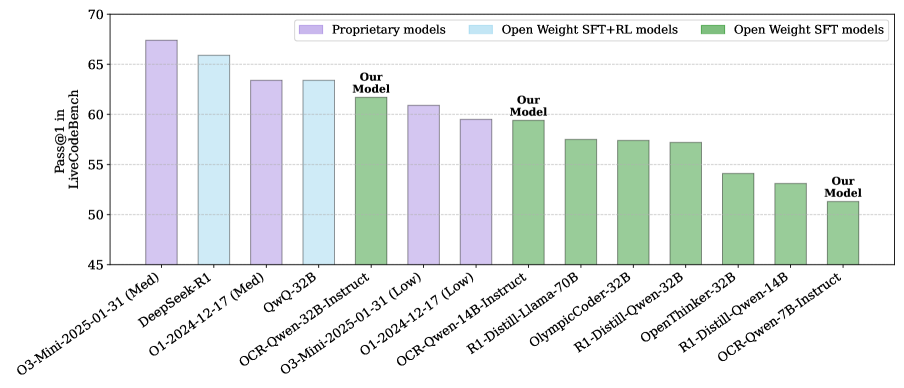
Comparison of pass@1 scores on LiveCodeBench for OCR-Qwen models versus R1-Distill-Qwen models across 7B, 14B, and 32B sizes.
Evaluation Highlights
- OCR-Qwen-32B achieves 61.8 pass@1 on LiveCodeBench, surpassing OpenAI's O1 and O3-Mini and narrowing the gap with the teacher model DeepSeek-R1 (65.6).
- OCR-Qwen-14B-Instruct attains 59.4 pass@1 on LiveCodeBench, outperforming the R1-Distill-Qwen-14B baseline (51.3) by 8.1 absolute points.
- OCR-Qwen-7B-Instruct scores 51.3 on LiveCodeBench, beating the R1-Distill-Qwen-7B baseline (38.0) by a massive 13.3 point margin.
Breakthrough Assessment
9/10
Establishes a new state-of-the-art for open-weight coding models via SFT alone, debunking the need for complex RL pipelines if data scale is sufficient. Outperforms OpenAI models in specific benchmarks.