📝 Paper Summary
Vision-Language-Action (VLA) Models
Robotic Manipulation
Reinforcement Learning (RL)
SimpleVLA-RL adapts Large Reasoning Model reinforcement learning techniques to robots, using simple binary success rewards to dramatically improve manipulation performance and generalization without expensive human data.
Core Problem
Training effective robotic policies via Supervised Fine-Tuning (SFT) requires scarce, expensive human-operated data and fails to generalize to unseen objects or environments.
Why it matters:
- Scaling robot learning is currently bottlenecked by the high cost of collecting human teleoperation trajectories (demonstrations).
- Current VLA models struggle with distribution shifts; they perform well on exact training setups but fail when objects or scenes vary slightly.
- Traditional robotic RL relies on complex, hand-crafted process rewards (e.g., 'distance to object'), which are hard to design and don't scale across diverse tasks.
Concrete Example:
In the LIBERO-Long benchmark, an SFT-trained model provided with only one demonstration per task achieves a success rate of only 17.1% because it overfits to the single example. In contrast, SimpleVLA-RL explores the environment to find a robust policy, reaching 91.7% success.
Key Novelty
End-to-End Online Rule-Based RL for VLA
- Adapts the GRPO (Group Relative Policy Optimization) algorithm from Large Language Models (LLMs) to Vision-Language-Action models, using only binary 'success/fail' outcome rewards.
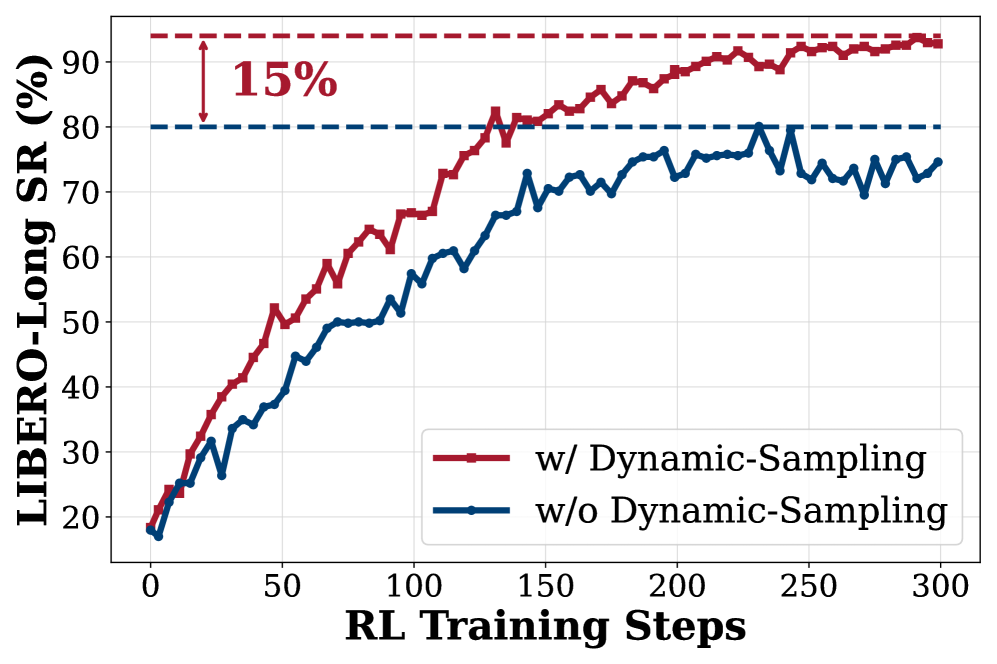
- Introduces exploration-enhancing mechanisms like 'Dynamic Sampling' (discarding batches with identical outcomes) and higher sampling temperatures to prevent the policy from collapsing into local optima.
Architecture
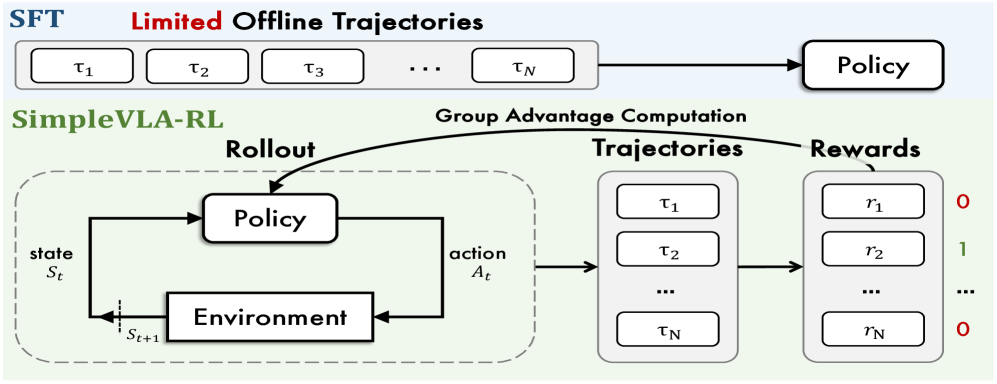
The SimpleVLA-RL training framework flow.
Evaluation Highlights
- Achieves 91.7% success on LIBERO-Long with only a single demonstration per task, compared to 17.1% for the SFT baseline (+74.6% improvement).
- Outperforms the state-of-the-art model π_0 (pi-zero) on RoboTwin 1.0 & 2.0 benchmarks.
- Exploration strategies (Dynamic Sampling, High Temp, Clip Range) yield consistent performance improvements of 10–15% over standard RL baselines.
Breakthrough Assessment
9/10
Successfully transfers the 'DeepSeek-R1' RL paradigm to robotics, demonstrating massive gains in data efficiency and generalization with a surprisingly simple reward structure.