📝 Paper Summary
Multimodal Large Language Models (MLLM)
Agentic AI
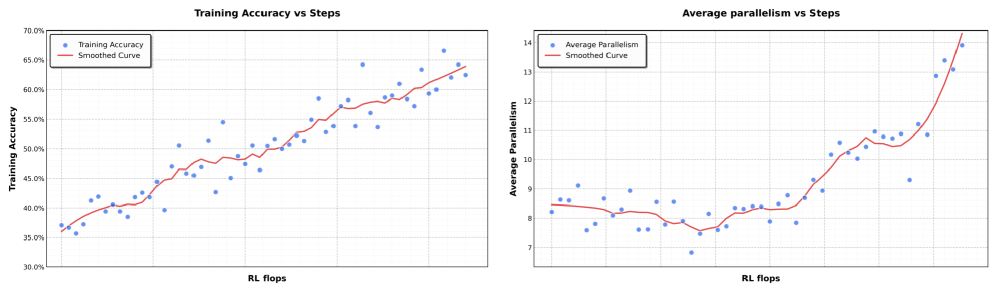
Parallel reasoning
Kimi K2.5 integrates early-fusion multimodal pre-training with a parallel agent framework (Agent Swarm) to enhance cross-modal reasoning and reduce inference latency for complex tasks.
Core Problem
Existing agentic models rely on sequential execution, causing linear latency scaling and context exhaustion, while traditional multimodal training often conflicts with or degrades pure-text capabilities.
Why it matters:
- Sequential agents become unacceptably slow and error-prone when handling massive-scale research or development tasks involving hundreds of steps
- Late-stage vision adaptation in standard Multimodal LLMs often treats vision as an add-on, failing to achieve deep grounding or actually hurting text performance
- End-to-end training of multi-agent systems suffers from credit assignment ambiguity (who caused the failure?) and instability
Concrete Example:
In a wide-search scenario requiring information from many sources, a sequential agent fetches each source one by one, hitting time limits. K2.5's Agent Swarm spawns sub-agents to fetch all sources simultaneously, aggregating results 4.5x faster.
Key Novelty
Agent Swarm with Parallel-Agent Reinforcement Learning (PARL)
- Decouples the orchestrator from sub-agents: the orchestrator is trained via RL to spawn and manage sub-agents, while sub-agents are frozen to stabilize training
- Uses 'Zero-Vision SFT' where text-only programmatic data activates visual tool-use capabilities without requiring potentially harmful human-annotated visual trajectories
- Joint Multimodal RL treats text and vision not as separate domains but as shared capabilities, where visual training signals improve pure-text benchmarks
Architecture
Conceptual flow of the Agent Swarm orchestration and PARL training loop
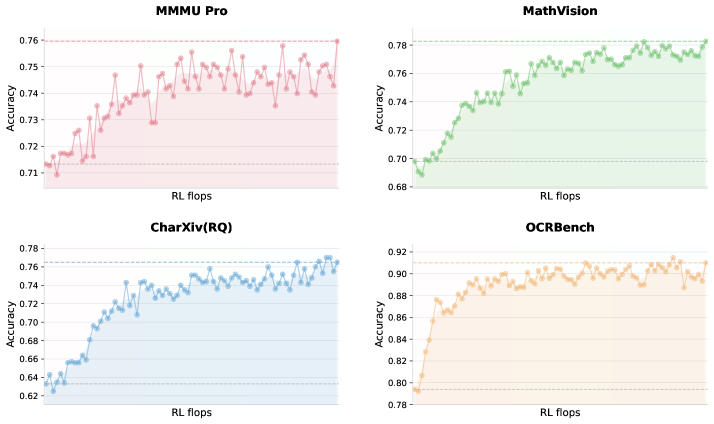
Evaluation Highlights
- Reduces inference latency by up to 4.5x in wide-search scenarios compared to single-agent baselines via Agent Swarm parallelism
- +2.1% improvement on GPQA-Diamond (84.3% -> 86.4%) after applying outcome-based visual RL, demonstrating cross-modal transfer to text tasks
- Improves item-level F1 score from 72.8% to 79.0% in complex wide-search tasks using the Swarm architecture
Breakthrough Assessment
9/10
Proposes a significant architectural shift from sequential to parallel agentic cognitive architectures (Swarm) and demonstrates a counter-intuitive finding that visual RL boosts pure text performance.