📝 Paper Summary
Code Generation
Reinforcement Learning (RL) for Code
AceCoder creates a large-scale dataset of automated test cases to train reliable reward models and perform reinforcement learning, significantly boosting the coding performance of base and instruction-tuned models.
Core Problem
Reinforcement learning (RL) has been underutilized in coding models because reliable reward signals (test cases) are scarce and existing datasets rely on expensive human annotation.
Why it matters:
- Evaluating code quality requires execution against test cases, but most large-scale datasets lack sufficient tests for robust reward modeling
- Existing reward models often fail to generalize to the coding domain due to the complexity of execution-based evaluation compared to simple text matching
- Current state-of-the-art open models lag behind proprietary models (like GPT-4) in coding tasks partly due to the lack of effective RL training pipelines
Concrete Example:
In math tasks, a simple string match against an answer key provides a reward. In coding, a generated program might look correct but fail edge cases. Without a suite of test cases (like those in AceCode-87K), an RL model cannot distinguish between a buggy solution and a correct one, preventing effective optimization.
Key Novelty
AceCoder (Automated Test-Case Synthesis for RL)
- Constructs a massive dataset (AceCode-87K) by prompting an LLM to 'imagine' test cases for existing coding questions, then filtering them using a strong proxy model to ensure validity
- Trains a reward model using execution pass rates on these synthesized tests to define preference pairs (e.g., distinguishing programs with >80% pass rates from those with <10%)
- Applies Reinforcement Learning (specifically Reinforce++) using both the trained reward model and direct test-case pass rates to optimize the policy
Architecture
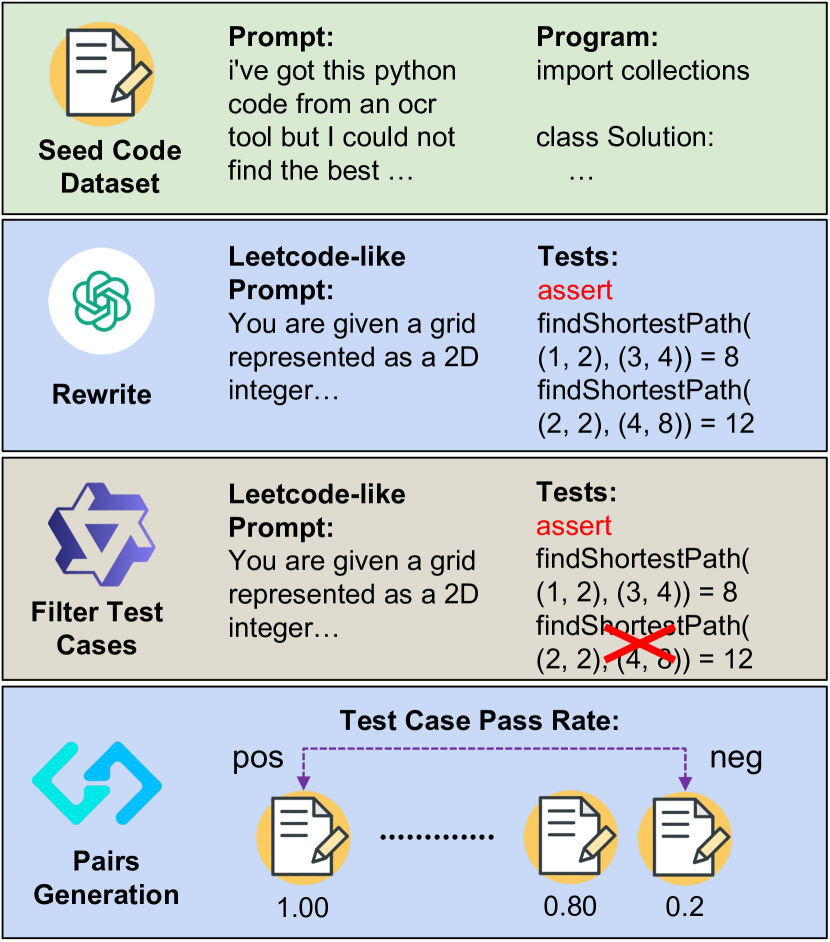
The automated data synthesis and RL pipeline.
Evaluation Highlights
- +10 points average improvement for Llama-3.1-8B-Instruct using AceCode-RM-32B Best-of-32 sampling across 4 major benchmarks
- +25% improvement on HumanEval-plus and +6% on MBPP-plus when performing RL directly from Qwen2.5-Coder-7B-base with only 80 optimization steps
- AceCode-RM-32B achieves a score of 76.1 on RM Bench, outperforming existing state-of-the-art reward models in Coding, Chat, and Hard categories
Breakthrough Assessment
8/10
Significantly democratizes RL for coding by automating the bottleneck (test case generation). The massive gains (+25% on HumanEval+) with minimal steps suggest this is a highly effective recipe for post-training.