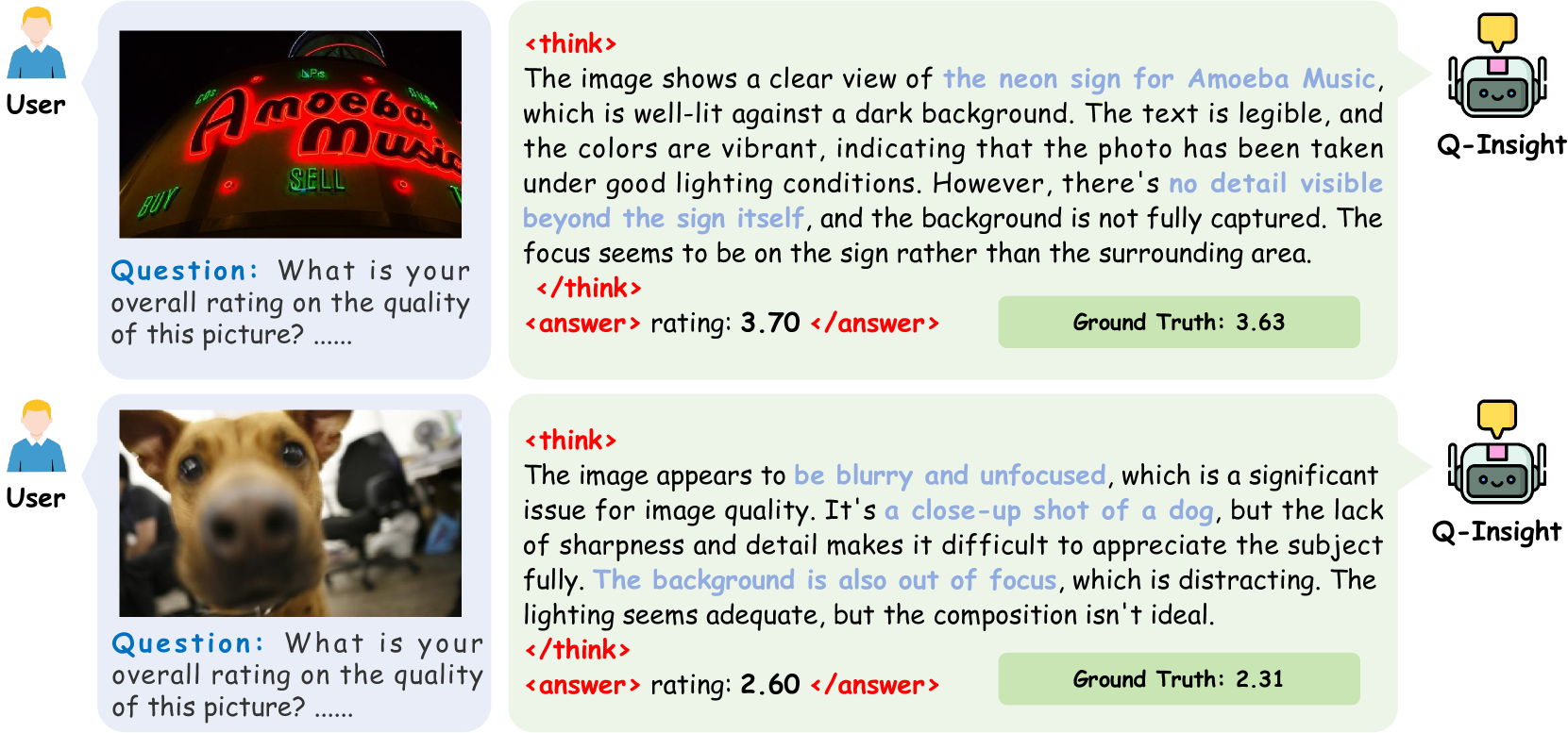
📝 Paper Summary
Image Quality Assessment (IQA)
Multi-modal Large Language Models (MLLMs)
Visual Reinforcement Learning
Q-Insight leverages Group Relative Policy Optimization (GRPO) to jointly train a multi-modal model on image scoring and degradation perception, enabling deep reasoning without extensive supervised fine-tuning data.
Core Problem
Existing MLLM-based IQA methods either output uninterpretable scores or rely on expensive, large-scale textual descriptions for supervised fine-tuning, limiting flexibility and generalization.
Why it matters:
- Pure score regression lacks transparency and fails to capture the subjective, nuanced nature of image quality (e.g., blur can be artistic or a defect)
- Description-based methods require massive human annotation effort and struggle to provide precise numerical rankings needed for downstream tasks
- Current models often fail to generalize to out-of-distribution (OOD) data or understand subtle low-level degradations like compression artifacts
Concrete Example:
When evaluating AIGC images, vibrant colors might imply high quality, but in super-resolution, the same features appear 'painterly' and low-fidelity. A standard regression model gives a score without context, while Q-Insight reasons about *why* the score is given based on the specific degradation context.
Key Novelty
Visual Reinforcement Learning for IQA via GRPO
- Adapts Group Relative Policy Optimization (GRPO) to visual quality tasks, allowing the model to self-explore reasoning paths using only final outcome rewards (scores/labels) rather than step-by-step supervision
- Jointly optimizes two distinct tasks—score regression and degradation perception—allowing the model to learn that identifying specific artifacts (like JPEG blocks) informs the overall quality score
Architecture
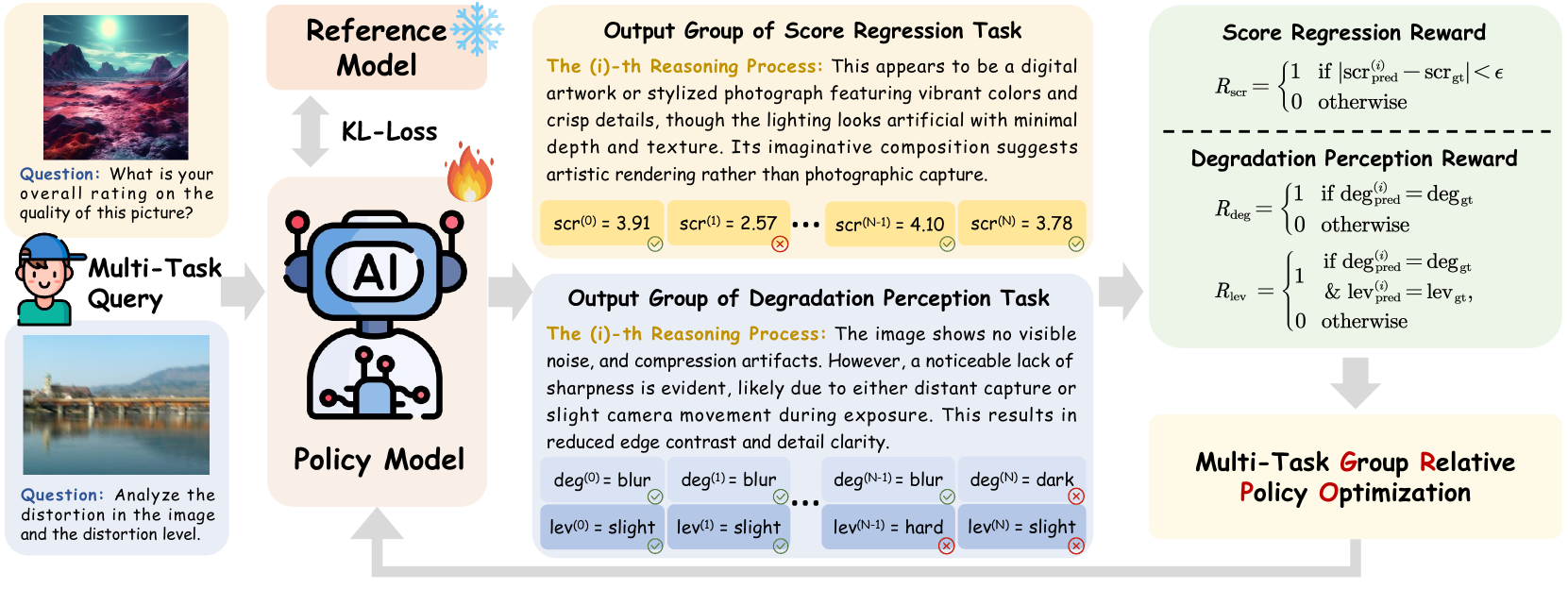
The Q-Insight framework using Group Relative Policy Optimization (GRPO) for joint score regression and degradation perception.
Evaluation Highlights
- Consistently outperforms state-of-the-art MLLMs (e.g., DeQA-Score) on out-of-distribution datasets (approx. +0.02 improvement in PLCC/SRCC)
- Achieves 92.77% average accuracy in degradation classification, significantly surpassing the fine-tuned baseline AgenticIR (59.98%)
- Demonstrates strong zero-shot generalization in comparative reasoning, outperforming description-based DepictQA by ~12% in overall accuracy on DiffIQA
Breakthrough Assessment
8/10
First application of GRPO to low-level visual quality understanding. Successfully replaces expensive textual SFT with efficient RL-based reasoning, showing strong generalization and multi-task benefits.