📝 Paper Summary
Machine Translation
Preference Optimization
LLM Fine-tuning
Contrastive Preference Optimization improves machine translation by training models to distinguish between high-quality and slightly flawed translations using preference pairs derived from reference-free evaluation, rather than just mimicking gold references.
Core Problem
Supervised Fine-Tuning (SFT) in machine translation is limited because it forces models to mimic 'gold' references that are often inferior to model-generated outputs, and it lacks a mechanism to teach models to reject near-perfect but flawed translations.
Why it matters:
- Training on imperfect human references caps model performance at the level of the data, preventing super-human performance
- Standard SFT does not penalize minor errors (like hallucinations or omissions) effectively because it only optimizes for likelihood of the reference
- Existing preference optimization methods like DPO are memory and speed inefficient for large translation models
Concrete Example:
In a FLORES-200 example, the human reference translation omits part of the source sentence information. However, SFT would force the model to learn this omission. A strong model (like GPT-4) generates a correct, complete translation. CPO allows the model to prefer the GPT-4 output over the flawed human reference.
Key Novelty
Contrastive Preference Optimization (CPO)
- Approximates Direct Preference Optimization (DPO) by assuming the reference policy is a uniform prior, eliminating the need to load a second reference model during training (memory efficient)
- Constructs 'gold' preference pairs dynamically using reference-free metrics (KIWI-XXL, XCOMET) to identify when model outputs are actually better than human references
- Adds a behavior cloning regularizer (standard negative log-likelihood) on the preferred data to ensure the model maintains generation capability
Architecture

The data construction and triplet selection process for CPO training.
Evaluation Highlights
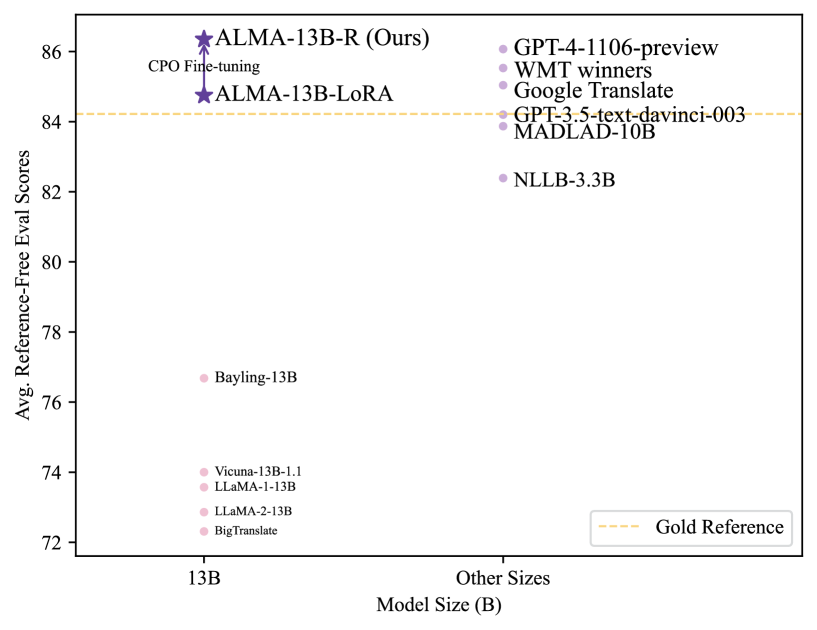
- ALMA-R (13B) matches or exceeds GPT-4 performance on WMT'21, WMT'22, and WMT'23 test datasets
- Achieves these results by tuning only 0.1% of parameters (12M params) using a small dataset of 22K parallel sentences
- Analysis reveals that model-generated translations (ALMA-13B-LoRA) are preferred over human 'gold' references 73.24% of the time by KIWI-XXL metric on xx->en tasks
Breakthrough Assessment
8/10
Significantly challenges the 'gold reference' dogma in MT and provides a highly efficient method (CPO) to surpass SOTA models with minimal parameter updates.