📝 Paper Summary
Tool-augmented Large Vision-Language Models (LVLMs)
Visual Reinforcement Learning
OpenThinkIMG enables LVLMs to adaptively employ visual tools for reasoning by combining a standardized distributed tool infrastructure with a reinforcement learning method (V-ToolRL) that optimizes for task success.
Core Problem
Current tool-augmented LVLMs rely on supervised fine-tuning (SFT) using static, expensive-to-generate trajectories, which fail to generalize to dynamic scenarios or unseen tools.
Why it matters:
- Heterogeneous tool definitions prevent standardized integration and reproducibility across different research efforts
- SFT lacks exploration mechanisms, meaning models cannot discover optimal tool-use strategies that differ from human-annotated templates
- Generating high-quality training data for tool reasoning is resource-intensive and often relies on brittle heuristics
Concrete Example:
In complex chart reasoning, an SFT-trained model might passively read the whole image and hallucinate a value. In contrast, the proposed V-ToolRL agent learns to actively invoke 'ZoomInSubplot' or 'DrawHorizontalLineByY' to precisely isolate and read the data point.
Key Novelty
V-ToolRL (Visual Tool Reinforcement Learning) and Distributed Tool Infrastructure
- Proposes V-ToolRL, an RL framework using Group-wise PPO (GRPO) that allows LVLMs to learn adaptive tool-use policies by optimizing directly for final answer correctness
- Introduces a distributed 'Tool Controller' architecture where tools run as independent containerized services, enabling flexible orchestration and parallel execution unlike monolithic tool libraries
Architecture
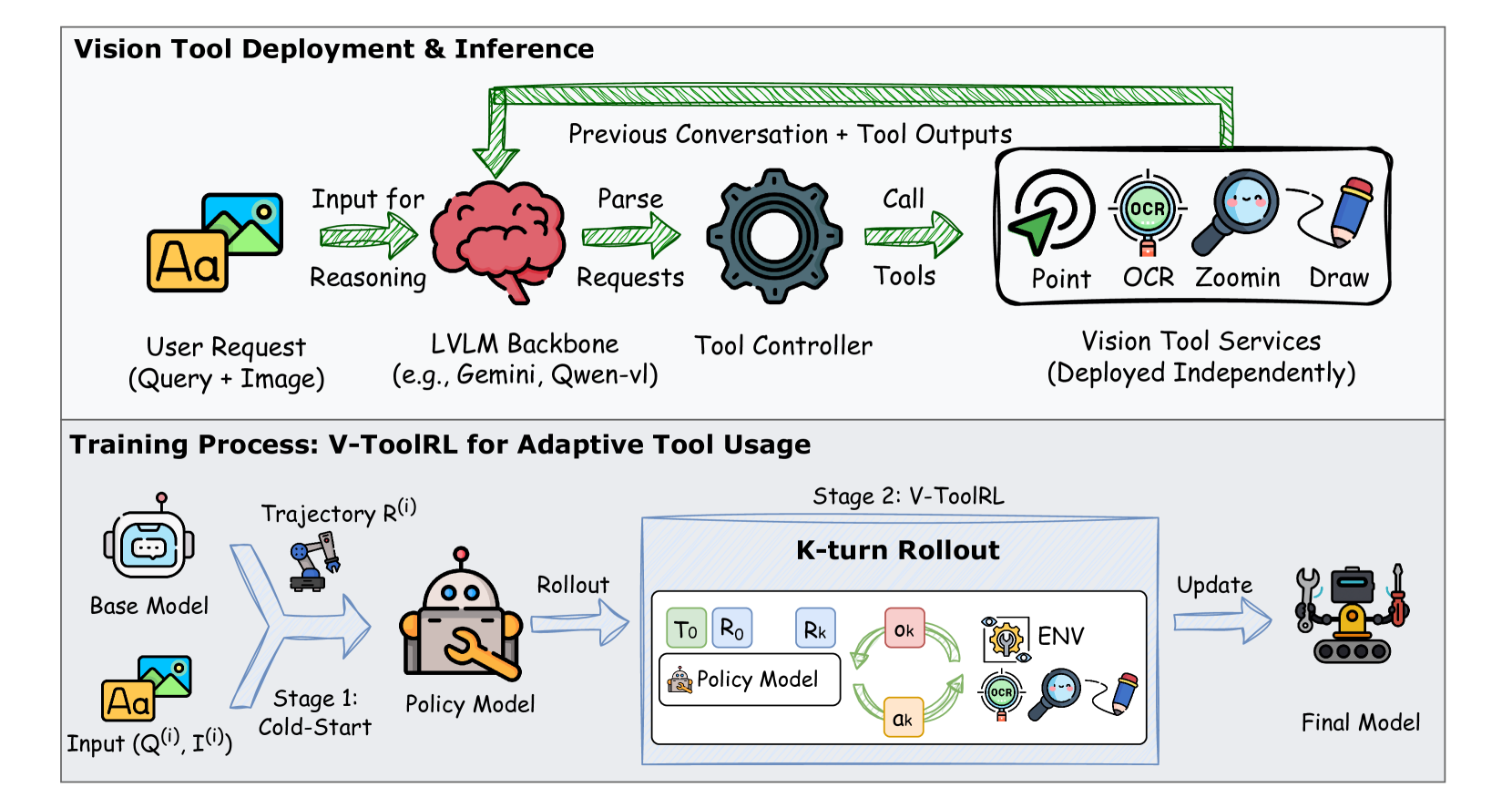
The OpenThinkIMG framework architecture, illustrating the interaction between the LVLM, the Tool Controller, and the Distributed Tool Services during inference and training.
Evaluation Highlights
- The V-ToolRL agent (Qwen2-VL-2B base) outperforms its own SFT-initialized counterpart by +28.83 points on chart reasoning tasks
- Surpasses established supervised tool-learning baselines (Taco and CogCom) by an average of +12.7 points
- Outperforms the prominent closed-source model GPT-4.1 by +8.68 accuracy points on the evaluated chart reasoning benchmarks
Breakthrough Assessment
9/10
Significant performance leap (+28 points) over SFT by applying RL to visual tool use, addressing the critical 'static trajectory' bottleneck in current multimodal agents.