📝 Paper Summary
Model Merging
Parameter-Efficient Fine-Tuning (PEFT)
Network Pruning
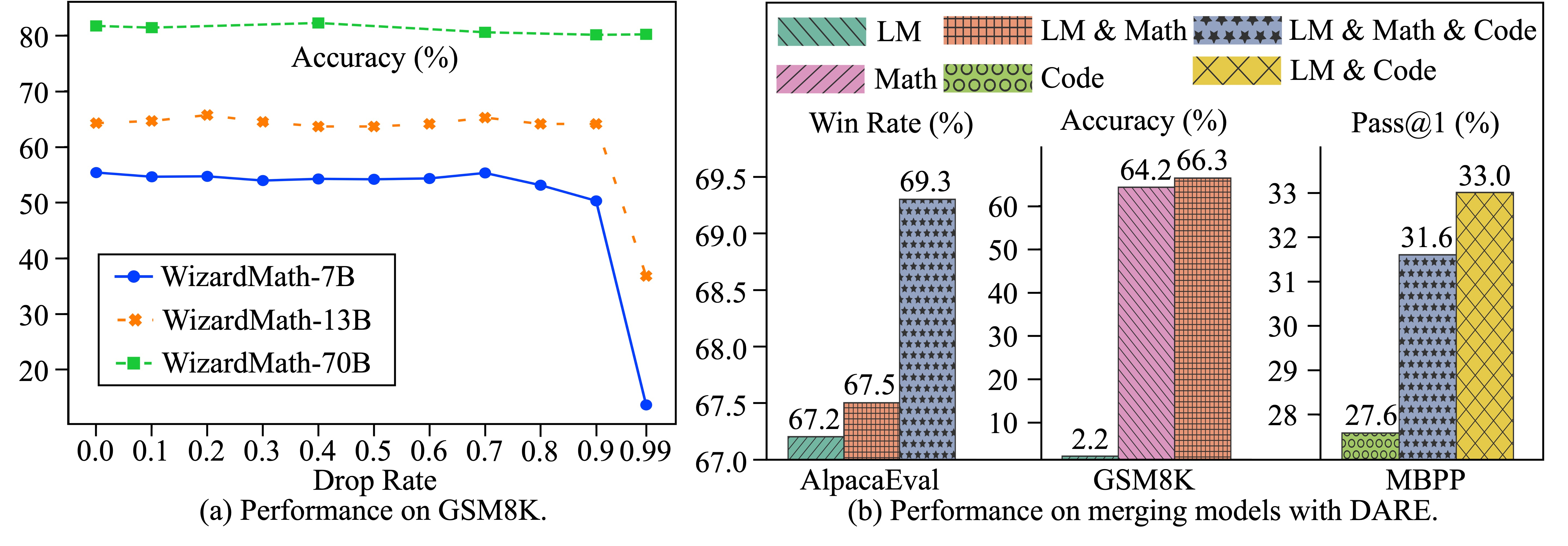
Language models fine-tuned on different tasks can be effectively merged into a single capable model by randomly dropping up to 99% of their delta parameters and rescaling the rest.
Core Problem
Merging multiple fine-tuned models often leads to parameter interference where one task's weights degrade another's performance, and standard SFT models contain massive parameter redundancy.
Why it matters:
- Training a single massive multi-task model is computationally expensive and inflexible compared to merging specialized expert models
- Current model merging techniques struggle with interference when combining models with overlapping parameter updates
- Understanding the redundancy in SFT updates reveals that fine-tuning primarily exposes existing capabilities rather than learning new complex features
Concrete Example:
When merging a Math-tuned Llama model and a Code-tuned Llama model, simply averaging their weights often degrades performance on both tasks due to conflicting parameter updates. DARE solves this by making the updates sparse (mostly zeros) so they don't overlap.
Key Novelty
DARE (Drop And REscale)
- Discovers that SFT delta parameters (fine-tuned minus pre-trained weights) are extremely redundant and small (< 0.002)
- Randomly drops p% of delta parameters (setting them to zero) and rescales the remaining ones by 1/(1-p) to maintain the expected value of feature embeddings
- Uses this sparsification as a pre-processing step for model merging, minimizing collisions between different task-specific updates
Architecture
Conceptual workflow of DARE and its application in model merging
Evaluation Highlights
- +19.57% improvement on MBPP (code generation) when merging LM, Math, and Code models compared to the Code model alone
- Maintains performance while dropping 99% of delta parameters for 70B models, showing extreme redundancy in SFT updates
- Achieved 1st rank on the Open LLM Leaderboard (7B parameter category) by merging diverse SFT models using DARE
Breakthrough Assessment
8/10
Significant empirical discovery regarding SFT redundancy. The method is incredibly simple (random drop + rescale) yet highly effective for merging, enabling 'free' multi-task capabilities without training.