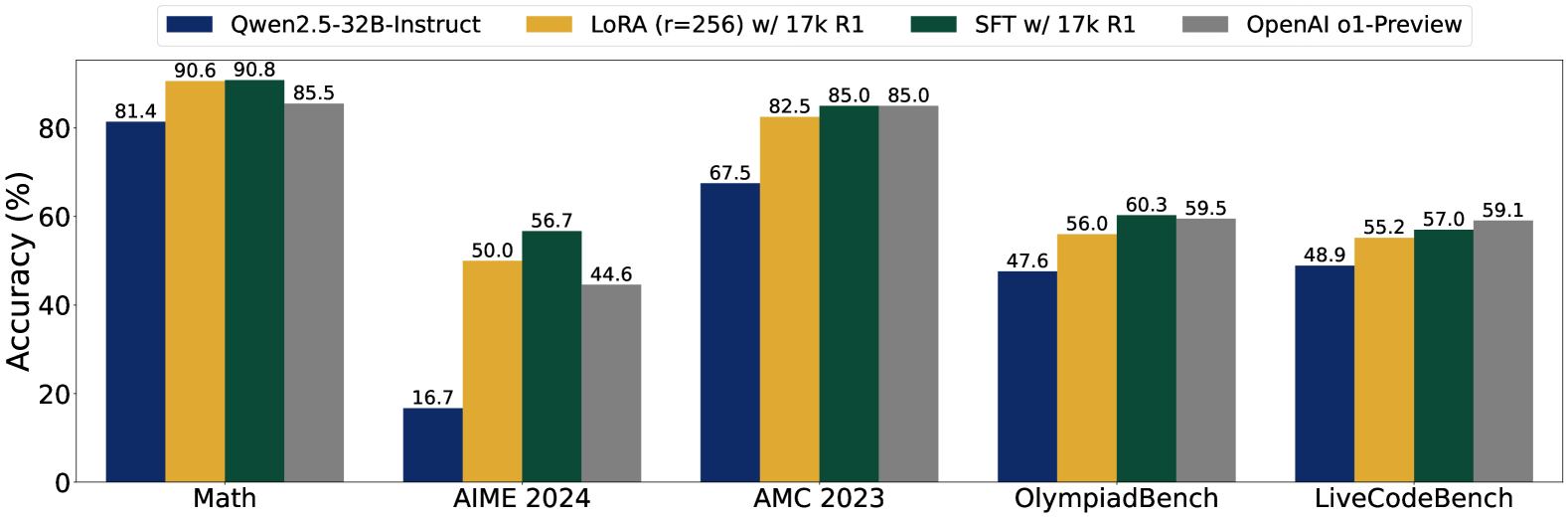📝 Paper Summary
Reasoning Distillation
Chain-of-Thought (CoT)
Parameter-Efficient Fine-Tuning
LLMs can learn complex reasoning behaviors from very few demonstrations using parameter-efficient fine-tuning, driven primarily by the global structure of the reasoning chain rather than the correctness of intermediate steps.
Core Problem
Training Large Reasoning Models (LRMs) typically requires expensive reinforcement learning or massive datasets, and the specific mechanisms that enable models to learn 'Long CoT' reasoning are poorly understood.
Why it matters:
- Existing high-performance reasoning models (like o1) are closed-source or prohibitively expensive to replicate
- It is unclear whether models need to learn deep domain knowledge or simply acquire structured reasoning patterns to succeed
- Understanding the minimal data requirements for reasoning allows for much cheaper and more accessible model training
Concrete Example:
A model trained on 'correct' reasoning traces (where every step is valid) achieves high accuracy. However, if you shuffle those same valid steps, destroying the logical flow, accuracy drops by 13.3% on AIME 2024. Conversely, training on traces with the *wrong* final answer but correct structure results in only a 3.2% drop.
Key Novelty
Structural Reasoning Distillation
- Demonstrates that the 'Long CoT' capability (reflection, backtracking) can be distilled into smaller models using only 17k samples via LoRA
- Crucial discovery that the *structure* of reasoning (logical coherence, use of 'wait'/'alternatively') is more important for learning than the factual correctness of the training content itself
Architecture

Comparison of the distilled model (Sky-T1-32B-Preview) against the base Qwen2.5 model and OpenAI's o1-preview on Math-500, AIME, and AMC benchmarks.
Evaluation Highlights
- +40.0% accuracy improvement on AIME 2024 (16.7% → 56.7%) using Qwen2.5-32B-Instruct fine-tuned on just 17k samples
- Achieves 57.0% on LiveCodeBench (+8.1% vs base), competitive with proprietary o1-preview (59.1%)
- LoRA fine-tuning updates <5% of parameters yet matches full fine-tuning performance, proving reasoning patterns are not knowledge-intensive to learn
Breakthrough Assessment
9/10
The counter-intuitive finding that models can learn strong reasoning from *incorrect* data (as long as structure is preserved) fundamentally shifts our understanding of instruction tuning and CoT.