📝 Paper Summary
Masked Diffusion Models (MDMs)
Preference Optimization
Diffusion Model Alignment
LLaDA 1.5 aligns large language diffusion models using Variance-Reduced Preference Optimization (VRPO), a framework that mitigates the high variance of ELBO-based likelihood estimates through optimal budget allocation and antithetic sampling.
Core Problem
Aligning diffusion models with DPO is challenging because exact log-likelihoods are intractable, and approximating them with ELBOs via Monte Carlo sampling introduces high variance that destabilizes the optimization.
Why it matters:
- High variance in likelihood estimates leads to noisy gradients, preventing diffusion models from effectively learning human preferences compared to autoregressive models
- The bias introduced by the non-linear DPO loss function is governed by this estimator variance, meaning high variance directly corrupts the optimization objective
Concrete Example:
When estimating the preference score for a winning response $y_w$ versus a losing response $y_l$, independent random sampling of diffusion timesteps and masks can produce a noisy score difference that flips the preference sign purely due to sampling luck rather than model quality.
Key Novelty
Variance-Reduced Preference Optimization (VRPO)
- Demonstrates theoretically that DPO loss bias and variance are bounded by the variance of the preference score estimator
- Allocates the sampling budget optimally by assigning all samples to distinct diffusion timesteps (one mask per timestep) rather than multiple masks per step
- Applies antithetic sampling by sharing the same random timesteps and masks between the model and reference policy to cancel out correlated noise in the score difference
Architecture
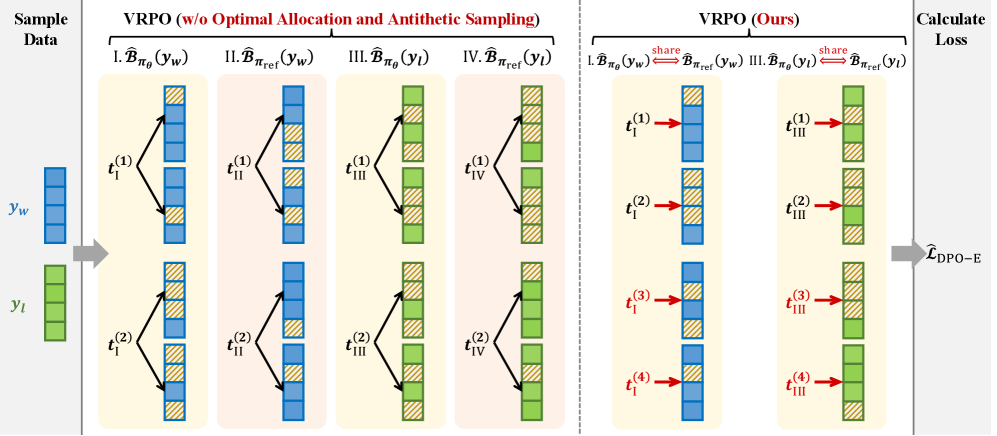
Illustration of the Variance-Reduced Policy Optimization (VRPO) techniques compared to standard estimation
Evaluation Highlights
- +4.7 improvement on GSM8K (Math) using LLaDA 1.5 compared to its SFT-only predecessor LLaDA 8B Instruct
- +4.3 improvement on Arena-Hard (Alignment/Chat) using LLaDA 1.5 compared to LLaDA 8B Instruct
- +3.0 improvement on HumanEval (Code) using LLaDA 1.5 compared to LLaDA 8B Instruct
Breakthrough Assessment
8/10
Identifies a fundamental theoretical hurdle in aligning diffusion models (ELBO variance in DPO) and provides a rigorous, principled solution (VRPO) that yields consistent empirical gains across multiple domains.